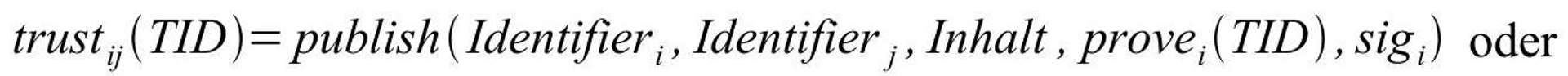A PKI based on decentralized trust for P2P transaction processing [2004]
Context
The text below is Malte Ubl's diploma thesis from 2004. Diploma was the name of the primary academic title for engineering degrees in Germany before Europe switched to the US Bachelor/Masters system.
The thesis was originally written in German which clearly was a mistake since the audience was the worldwide computer science community. In fact, I've been sad about this decision ever since. AI to the rescue. The text below is machine-translated by Google's Gemini 1.5 Pro.
Publishing the thesis now has no practical purpose, but it is a fun historical artifact providing a perspective into the early-2000s internet. Summarized with the benefit of hindsight, the thesis proposes a blockchain-like mechanism for p2p transaction processing.
The text has a lot of boilerplate establishing baseline facts required for diploma theses. Things get a bit more interesting from 6 Trust.
1 Introduction
2004 - The Internet has changed the world. The World Wide Web has driven globalization forward at an unprecedented speed, often completely eliminating the spatial distance between business partners. Who can deliver a truckload of coffee machines to my receiving dock next Wednesday? This question can be easily posed on international marketplaces today. The advantages for companies are obvious, but entirely new possibilities are also emerging for consumers. Abercrombie & Fitch doesn't have outlets in Germany - so I'll just order from the USA. Your daughter has outgrown her Barbie dolls - auction won. Global freedom is what the Internet gives us - and yet this freedom is currently limited. Even the seller on eBay is a customer of a paid service. People on the Internet are primarily users and only secondarily providers.
Wouldn't you think a computer with 2 gigaflops of processing power, half a terabyte hard drive, and a 3 Mbit DSL Internet connection is good for more than just displaying a web browser on the screen? These previously untapped resources of the Internet enable a migration away from the client-server architecture towards a peer-to-peer (P2P) architecture. This thesis will show a concrete way how, based on current technology, a network can be created that emancipates people on the Internet from their role as mere users. The monopoly of companies on providing services is broken and made accessible to the masses - the technology represents at least a paradigm shift, if not a revolution.
The goal of this thesis is to enable participants in a fully decentralized P2P network to efficiently conduct business processes with each other. After a brief introduction to the world of P2P networks, the thesis first addresses the elementary technological building blocks that support the execution of complex business processes in computer networks. One building block is enabling verifiable communication or electronic signatures as a prerequisite for contract conclusions in virtual space. However, this purely technological level is not the only area that makes trading in P2P networks a challenge. In a global market, the issue of trust between the participants in a transaction is crucial because only where trust exists can efficient, spontaneous decisions be made without unnecessary caution. In contrast to traditional business contacts, however, the factor of personal relationships is eliminated. Therefore, there must be novel procedures within the network to create trust relationships between participants. Such decentralized trust management forms the second building block for business processes in P2P networks.
An interesting characteristic of P2P networks is that while the network as a whole is practically unlimitedly available, the connections of individual participants are very unstable. This contrast contradicts the assumptions made in the traditional client-server architecture. Existing technologies are therefore often partially unsuitable for use in P2P networks. Filling this technology gap is a central part of this thesis. One step in this direction is the introduction of P2P transactions. P2P transactions allow, for the first time, participants in a network with extremely unreliable connections to conduct transactions with each other, after which both the client and the provider of a transaction can prove that the transaction took place and what the result of the transaction was. In conjunction with decentralized trust management, P2P transactions therefore form a solid infrastructure for conducting business processes in P2P networks.
For a more vivid presentation, the procedures and methods in this thesis are considered using a consistent scenario - a C2C online auction platform. However, the developed infrastructure could pave the way for a variety of applications into the P2P world - a step that is very attractive, not least for business reasons.
2 P2P Networks
Peer-to-peer (P2P) networks themselves are not a new concept. For example, the mail delivery protocol SMTP^(1){ }^{1}and even the DNS protocol^(2){ }^{2}, the backbone of the Internet as we know it today, are P2P protocols. The name "P2P", however, has only emerged in recent years. It makes it easier to talk about a phenomenon that has been particularly associated with copyright infringement by the general public since the late 1990s, but which technologically represents a paradigm shift that will lastingly change the role of every single "Internet surfer". Brookshier writes in this sense that P2P technology is not a new concept, but a revolution. A revolution not in the technical sense - but a revolution like the French Revolution.^(3){ }^{3}The participant in a P2P network is the emancipated Internet user. The concentration of resources on the servers in the client-server model gives way to a system in which each participant can assume the role of either the server or the client, depending on the situation.^(4){ }^{4}
2.1 Roles of Network Participants
A special feature of the P2P architecture is the role distribution of the participants in the network. This will be presented here in contrast to the client-server architecture.
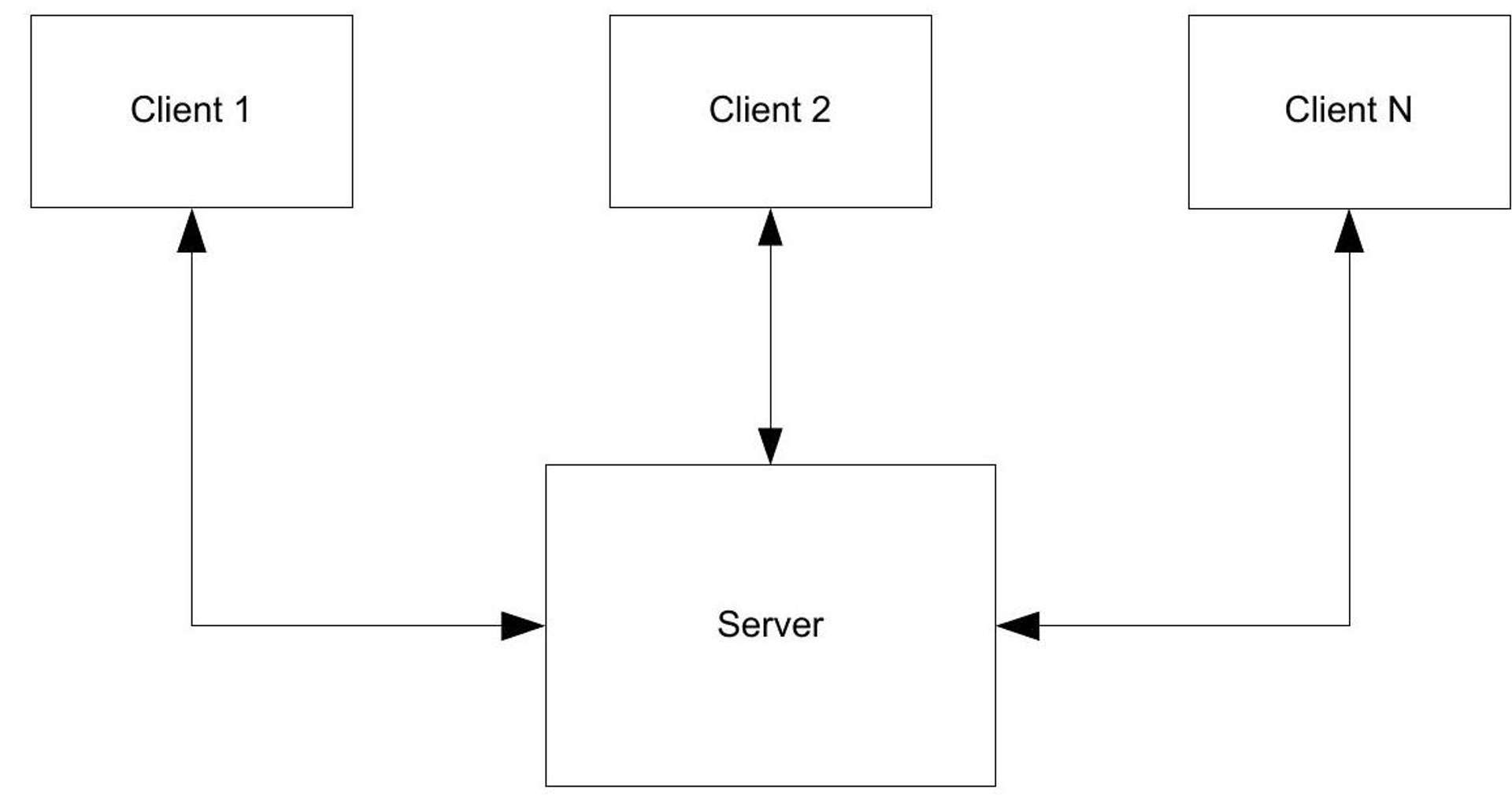
The computers in a network built according to the client-server architecture can be divided into those that assume the role of clients and those that assume the role of servers. The number of clients is usually significantly larger, while the servers are particularly powerful computers. The clients provide the user interface, while the network services (for example, print service, file service, and database service) run on the servers. There is no direct communication between the clients.^(5){ }^{5}
Figure 1: Data flows in a client-server network.
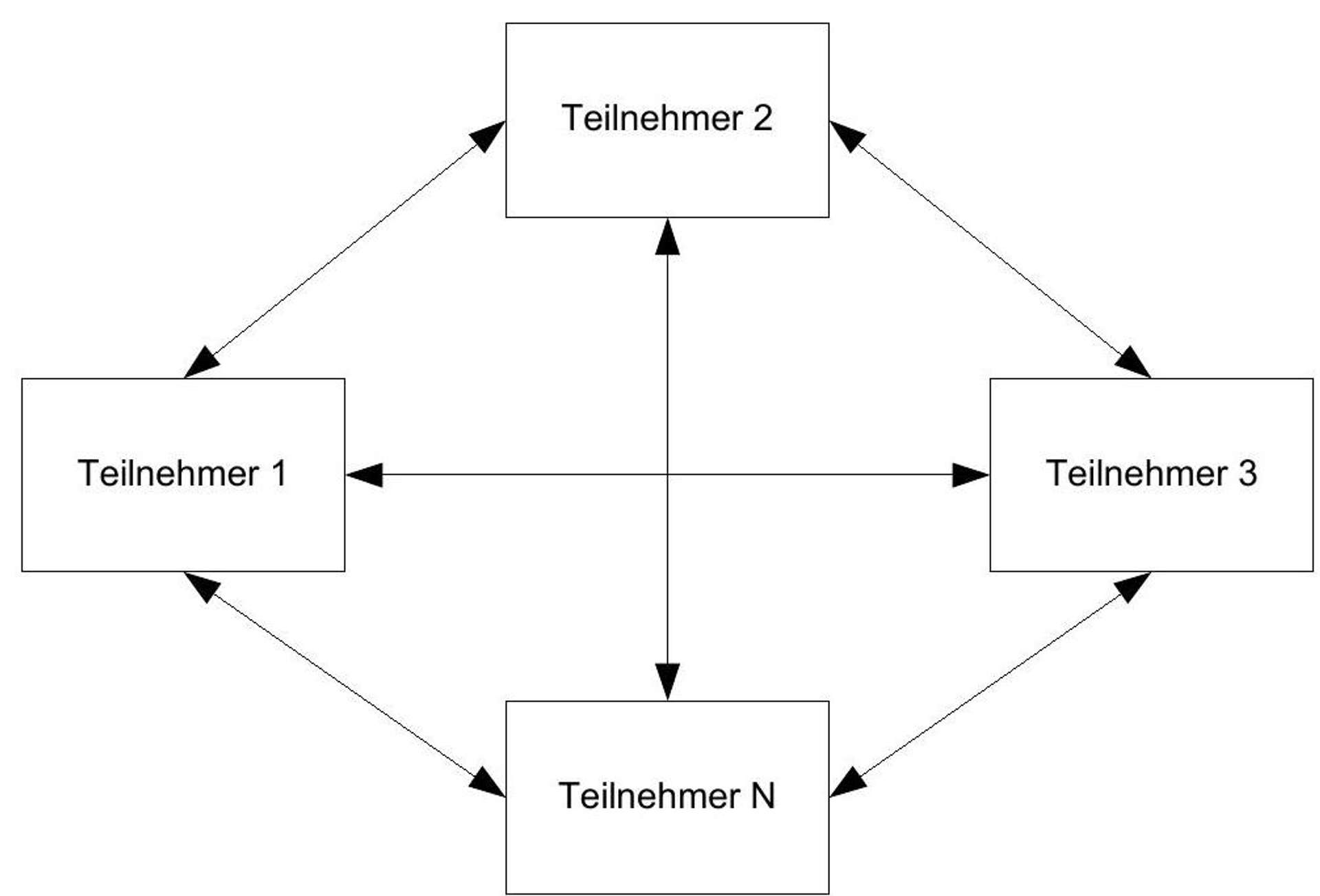
In a P2P network, such a clear distinction between client and server cannot be made.^(6){ }^{6}Each participant in the network has a user interface for client functionalities and offers services for other participants in the network. Ideally, every participant should be able to offer every transaction supported by the network.^(7){ }^{7}
Figure 2: Data flow in a P2P network.
A P2P network thus forms a kind of community in which members "pay" for the use of other members' resources by making their own resources available.^(8){ }^{8}
2.2 Organization
A pure P2P network is organized entirely decentrally. There is no central unit (e.g., a server) that acts as a coordinator; rather, the network's behavior is the product of the independent behavior of the participants. Due to the lack of a controlling entity, a P2P network requires a kind of incentive system^(9){ }^{9}that guides the behavior in the network in a common direction.^(10){ }^{10}P2P networks that deviate from the strict decentralized organization are called hybrid P2P networks. The choice of a hybrid structure is usually made to improve performance when a distributed algorithm is significantly less efficient than a comparable centralized algorithm. However, this step introduces a single point of failure, which reduces the network's robustness to failures.^(11){ }^{11}
So-called super-peer P2P networks are a hybrid of the pure P2P architecture and a hybrid structure. In such a network, the super-peers take on more tasks than ordinary participants. One can speak here of several P2P networks at different hierarchical levels. Depending on the size and openness of the individual levels, the complexity, degree of organization, and robustness of the individual levels can be manipulated.^(12){ }^{12}
In the following, only decentrally organized P2P networks will be considered.
2.3 Structuring
P2P networks can be differentiated according to their degree of structuring. In an unstructured P2P network, participants have no information about the resources of other participants. This means that, for example, searching the network is only possible by sending a request to as many other participants as possible. Unstructured P2P networks are extremely fault-tolerant, as the failure of a single participant has no effect on the overall system. However, this comes at the cost of efficiency and predictability of system behavior.
In structured P2P networks, participants have knowledge about the available resources of a set of other participants. This enables efficient routing mechanisms (e.g., for searching), which are implemented, for example, by distributed hash tables.^(13){ }^{13}Managing this information represents an additional effort. This is all the more true since the information must be constantly adjusted when participants leave or join the network.^(14){ }^{14}
2.4 Differentiation from Other Distributed Architectures
In addition to P2P networks, there are other distributed computer network architectures, which will be contrasted here with P2P networks for better differentiation.
2.4.1 Clusters
A cluster is a parallel and possibly distributed system consisting of a set of computers that are used as a single, unified computing resource. A cluster thus has an external effect like a single computer. The distribution of tasks and resources within the cluster is carried out by a central entity, and the computers usually belong to a single local network.^(15){ }^{15}Compared to P2P networks, clusters therefore differ particularly in terms of spatial distribution and organization. While the computers in a cluster are coordinated by a central unit to work towards a specific goal, the behavior of the participants in a P2P network is not subject to central control. In this respect, a cluster works much more purposefully than a P2P network, but scalability is limited by two decisive factors. Only as many computers can be added to the cluster as the central control can handle and as the owner can finance. The central control limits the availability of the cluster because the failure of the control puts the entire system out of operation.^(16){ }^{16}
2.4.2 Grid Computing
A grid is a parallel and distributed system that allows geographically distributed, autonomous participants to share their resources. The distribution takes place dynamically at runtime based on various criteria such as the availability and computational speed of the participants.^(17){ }^{17}The participants often belong to different organizations. However, the degree of organization between the participants is usually quite high. Current implementations of grid computing networks often still use centralized mechanisms for resource management. However, a decentralized implementation with P2P technology is also possible. Such grid computing networks are then special forms of P2P networks specifically designed for the distribution of resources.^(18){ }^{18}
2.5 Advantages and Disadvantages of P2P Technology
From a business perspective, operating an application for end-user use based on a P2P network offers significant advantages over a client-server architecture. Since the systems control themselves and data is exchanged directly between participants, all costs associated with operating the application are eliminated. This particularly affects costs for operating a data center or for traffic caused by customers.
A disadvantage of P2P technology is that the provider of a P2P network has little influence on the events taking place within it. Also, developing a P2P application is generally significantly more complex than developing client-server applications, although this could change with the development of P2P frameworks like JXTA^(19){ }^{19}.
Fully decentralized P2P networks are practically unlimitedly available because the failure of individual participants does not affect the functionality of the entire network. The scalability of P2P networks with respect to a given problem depends on the existence of suitable algorithms for use in decentrally organized, distributed environments. However, there is no bottleneck in P2P networks that would impose an upper limit on performance. In this respect, P2P networks are infinitely scalable.
2.6 Applications
In addition to the examples DNS and SMTP mentioned above, P2P networks are found in the following areas today:^(20){ }^{20}
File sharing - controversially represented by Napster^(21){ }^{21}, Kazaa^(22){ }^{22}, Gnutella^(23){ }^{23}, etc. Exchange of often copyrighted content over the P2P network.
Content distribution - represented by BitTorrent^(24){ }^{24}, among others. Distribution of the traffic load of a download, which is accessed by many, among all downloaders.
Resource sharing - represented by SETI@Home^(25){ }^{25}, among others. Participants make their unused resources available to the network.
Communication - represented by ICQ^(26){ }^{26}, among others. Participants communicate with each other via direct channels.
2.7 Characteristics
For a more efficient presentation, this thesis uses the term P2P network as a synonym for a hypothetical network with characteristics that can be considered realistic for a P2P network based on existing P2P networks. The characteristics are: /P2P 10/ Every participant can, in principle, carry out every transaction supported by the P2P network. /P2P 20/ Participants can publish information in the network. /P2P 30/ Information is kept massively redundant. Its availability is therefore independent of the online status of a single participant. /P2P 40/ Information in the network can be searched efficiently and decentrally. /P2P 50/ All participants can communicate unhindered. In particular, the existence of firewalls is ignored for simplification.^(27){ }^{27} /P2P 60/ In contrast to the availability of information throughout the network (/P2P 30/), there are no guarantees regarding the availability of a single participant. It must be assumed that participants regularly drop out.
The contrast between the characteristics /P2P 30/ and /P2P 60/ is one of the most striking characteristics of P2P networks. The network as a whole is highly available, while individual participants switch between online and offline status at relatively short intervals. The average online time of a participant in a P2P file-sharing network is approximately 60 minutes.^(28){ }^{28}The maximum online time of participants is limited by most Internet providers used by end customers, as the internet connections are closed after a maximum of 24 hours. This volatility of connections makes many mechanisms developed for highly available network topologies unsuitable for use in P2P networks.
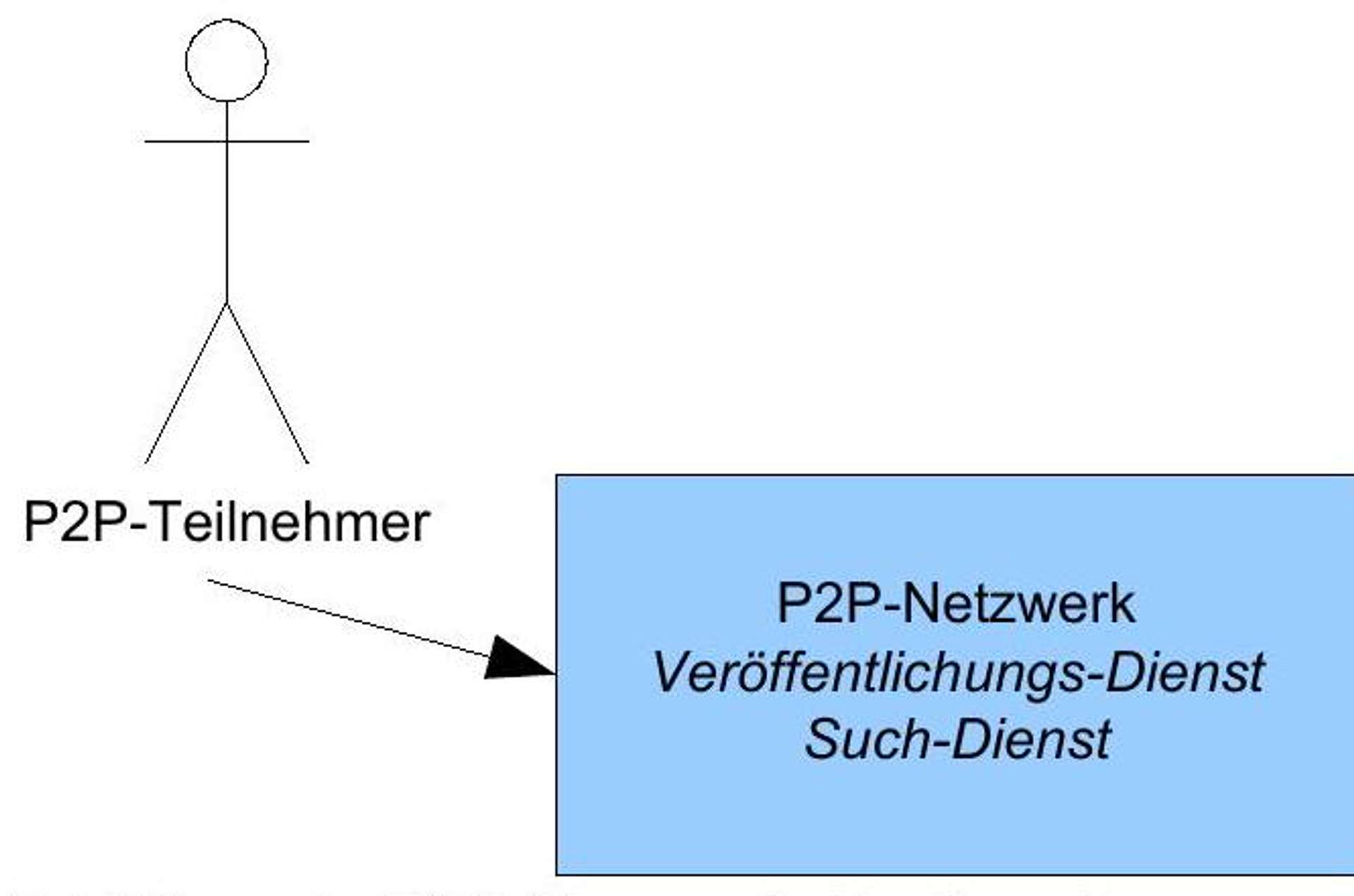
From the characteristics /P2P 20-40/, it follows that the P2P network as a whole represents a kind of distributed database that provides services for publishing and searching for information.
Figure 3: P2P network as an abstract server.
To facilitate the presentations and visualization, the P2P network will therefore be represented in figures (see Figure 3) in the following as a simple server that is available to the participants. The characteristic of massive spatial distribution is, however, ignored.
2.8 Identifiers
An identifier is a string that identifies an entity in a network. Unless otherwise stated, it is globally unique in the sense of the network. The identifier for an entity iiis called Identifier _(i)_{i}.
2.9 Functions
Based on the characteristics mentioned above, the P2P network provides some functions: The term tuple is used for related lists of data that can be passed to and returned from functions. For efficient representation, any declaration of data types is omitted. The contents of the tuples should be clear from the context.
publish(Tuple)
Every participant can publish any tuple of information in the network (/P2P 20/).
Participant iisends Tuple _(1)_{1}to participant jjand receives Tuple _(2)_{2}back as a response.
The functions together serve as an interface to the underlying network. They therefore represent a further level of abstraction between the transport layer and the application layer of the network.
3 Scenario
3.1 Business Perspective
This thesis deals with the establishment of an infrastructure for P2P networks that, among other things, supports the processing of business processes between participants. For a more vivid presentation, the facts are presented using a scenario.
Since all participants are technically on the same level in P2P networks, such business processes can be most easily mapped onto P2P networks in which the participants are also on the same level. This is true for hardly any business process more than for consumer-to-consumer online auctions. Here, each participant can be both a consumer and a provider, and the knowledge of each participant about the other participant is so limited that, for example, social differences hardly come into play.
Online auctions offer the advantage over other sales processes that they come very close to the economic ideal of perfect competition. Both the number of buyers and the number of sellers is large. For example, while online shops of well-known brands may reach a similar number of buyers, the number of sellers is always vanishingly small in comparison.^(29){ }^{29}
3.1.1 Business Process
This thesis considers C2C online auctions in the simplest possible form. The auction determines the price for a good through bids from potential customers. Each bid must be higher than the previous one. By placing a bid, the bidder declares their agreement to enter into a purchase contract at the bid price. The purchase contract is concluded if the bid is not exceeded.^(30){ }^{30}
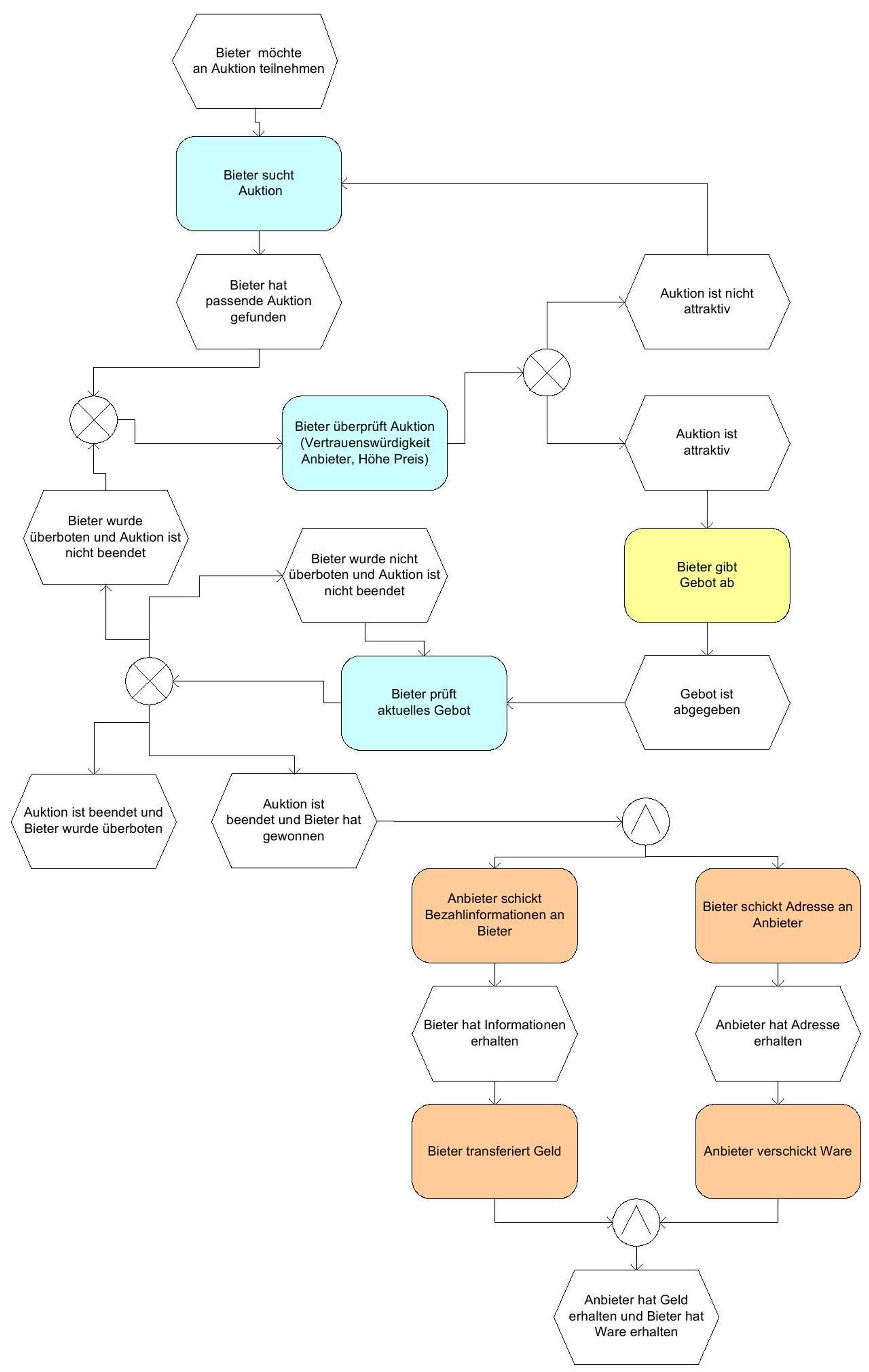
Figure 4: Online auction business process as EPK (see [Schröder 2004]); (Color coding is for categorization only).
The business process of an online auction can be roughly divided into three parts, assuming that a number of providers have already created and published auctions.
Offer selection (marked turquoise in Figure 4)
Bid submission (marked yellow)
Exchange of money for goods (marked orange)
This thesis is limited to the consideration of offer selection and bid submission, as the exchange of money for goods would primarily take place outside the computer network anyway. The submission of bids until the winner of an auction is determined is called an auction transaction. Once the auction transaction is completed, the provider and the winner can submit an evaluation of the auction process, whereby they can, of course, also take into account the subsequent exchange of money for goods.
3.1.2 Assumptions
The following assumptions are made for the online auction under consideration: /Ann 10/ The number of buyers is large. /Ann 20/ The number of sellers is large. /Ann 25/ The number of offers is large. /Ann 30/ All buyers have the same opportunity to sufficiently inform themselves about the offers. /Ann 40/ The offers can be easily compared with each other. /Ann 50/ The large number of buyers and sellers makes it very unlikely that a buyer and a seller know each other directly. /Ann 60/ The majority of participants are benevolent.
3.1.3 Data Modeling
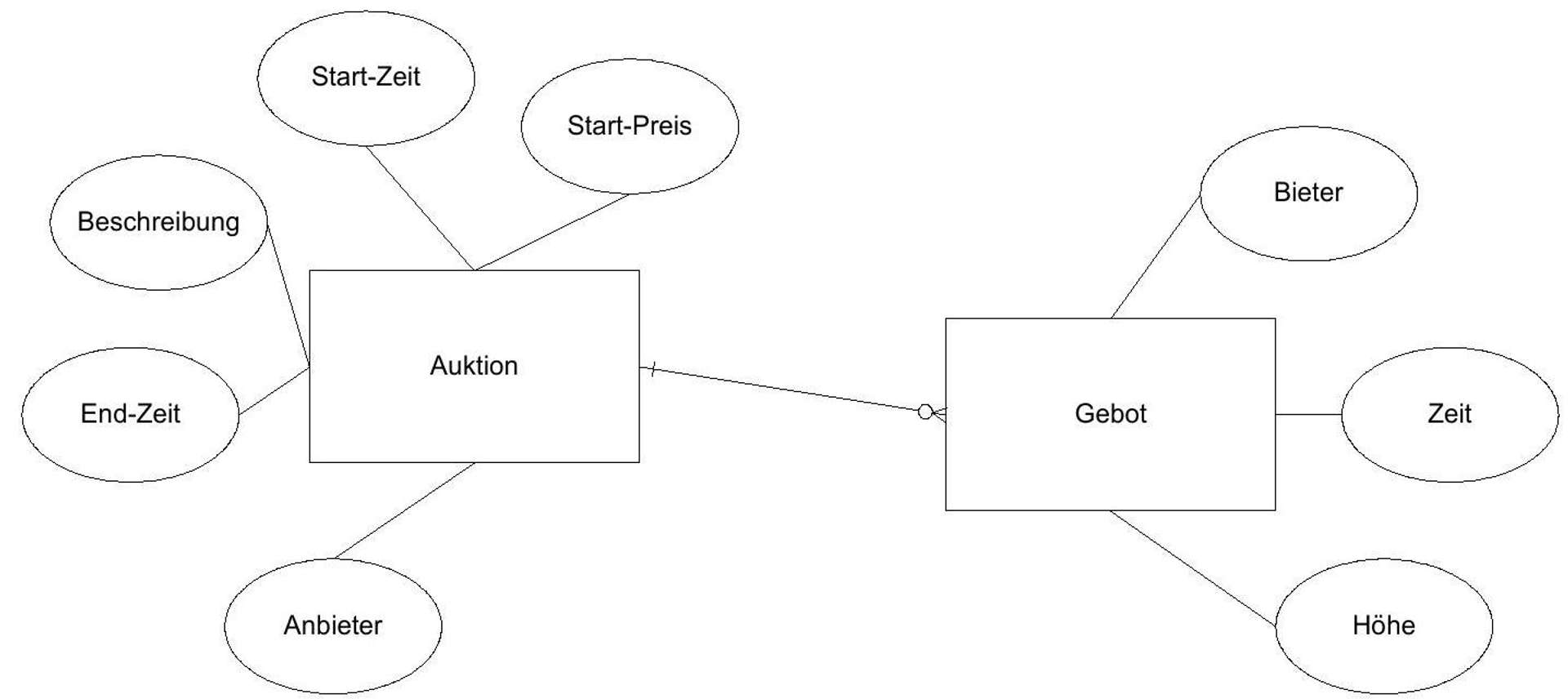
Figure 5: Modeling an auction as an ER diagram (see [Wikipedia Entity-Relationship Model]).
Figure 5 shows - in a greatly simplified form - the data of an auction platform (the description of the auction is arbitrarily complex. It can contain text, images, etc.).
3.1.4 Risk
All participants in an auction, both the seller and all bidders, have an interest in not being cheated. For the bidder, the question arises whether the seller will actually send the auctioned item after the money has been transferred and whether the quality of the goods corresponds to the auction description. As a seller, it is important whether the bidders actually have an interest in purchasing the goods or whether they only want to artificially drive up the price to benefit their own auctions. Another scenario would be that a bidder participates in several auctions for similar goods and chooses the cheapest offer in the end. Certainly, not all possible misbehaviors have been listed here, but the problem can be reduced to the fact that there must be a basis of trust between bidder and seller that allows participants to assess the risk of a transaction. In general, the decision to participate in a transaction or to allow another's participation will boil down to the formula:
Risk of transaction * Value of goods > Pain threshold for loss
Each participant will define the pain threshold for a loss for themselves. The value of the goods is known. However, /Ann 60/ makes assessing the risk difficult. An online auction platform must therefore support the determination of the risk of a transaction between complete strangers.
3.1.5 Requirements
The following requirements are placed on an auction platform: /Anf 10/ Participants must be able to create and publish auctions. /Anf 20/ Participants must be able to search for auctions. /Anf 25/ Participants must be able to determine the amount of the current bid. /Anf 30/ Participants must be able to assess the risk of a transaction with another participant. /Anf 40/ Bidders must be able to submit bids.
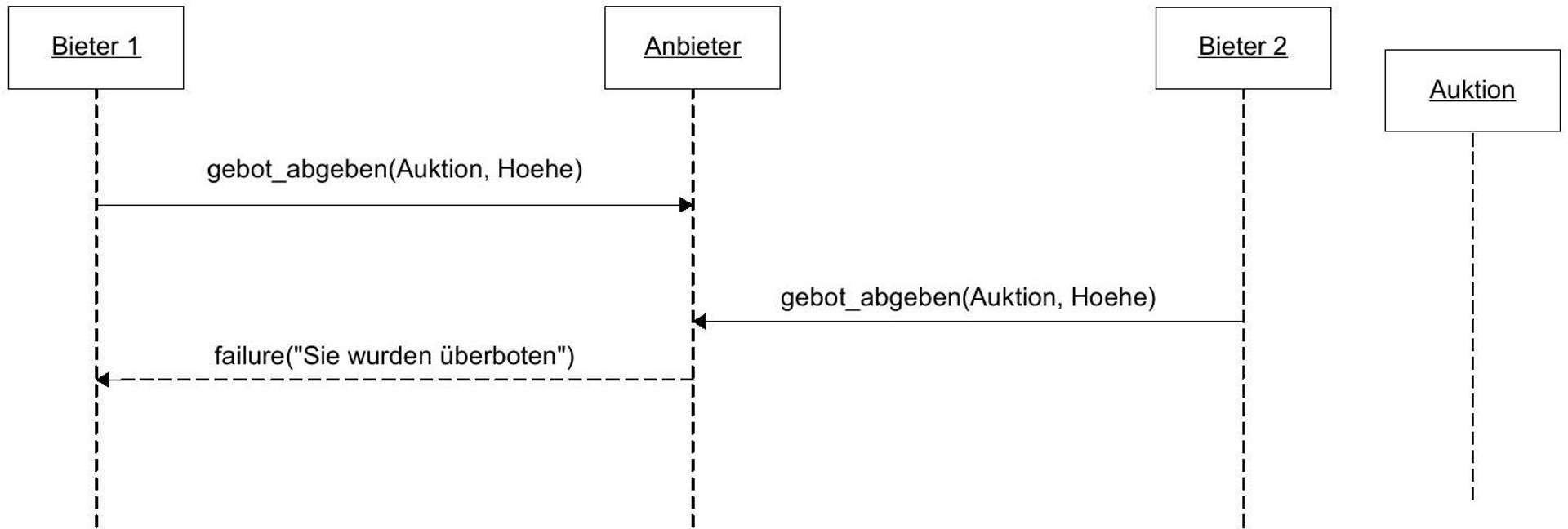
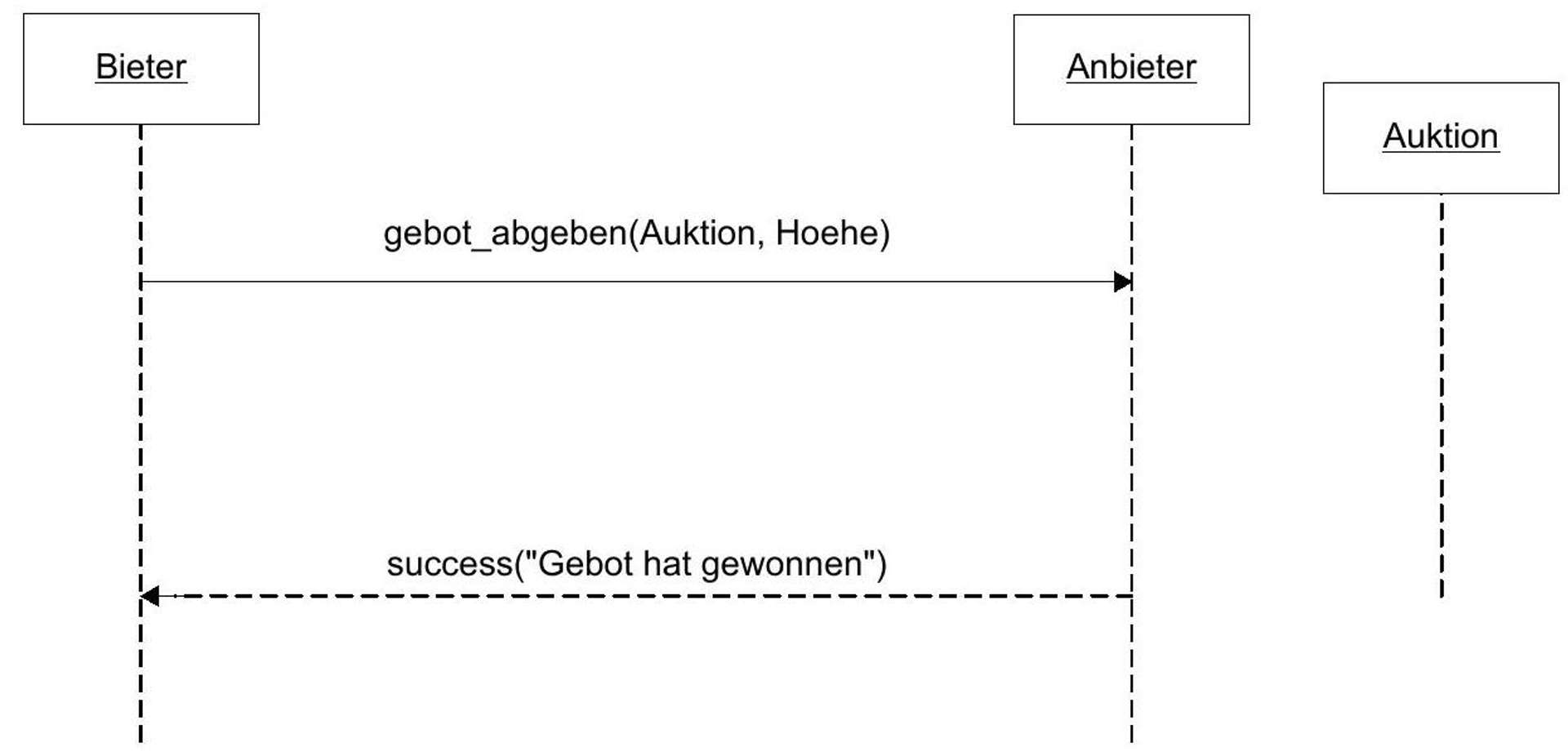
Submitting a bid is the transaction in the narrower sense. The following requirements apply to this: /Anf 50/ The bidder must have proof that they have submitted a bid. /Anf 60/ The seller must have proof that the bidder has submitted a bid. /Anf 70/ If the bidder and seller are honest, the evidence from /Anf 50/ and /Anf 60/ must never contradict each other.
For /Anf 10/ up to but not including /Anf 30/, it is assumed that these requirements can be met by the capabilities of today's widespread file-sharing P2P networks. The remaining requirements will be addressed in this thesis.
3.1.6 Use Cases
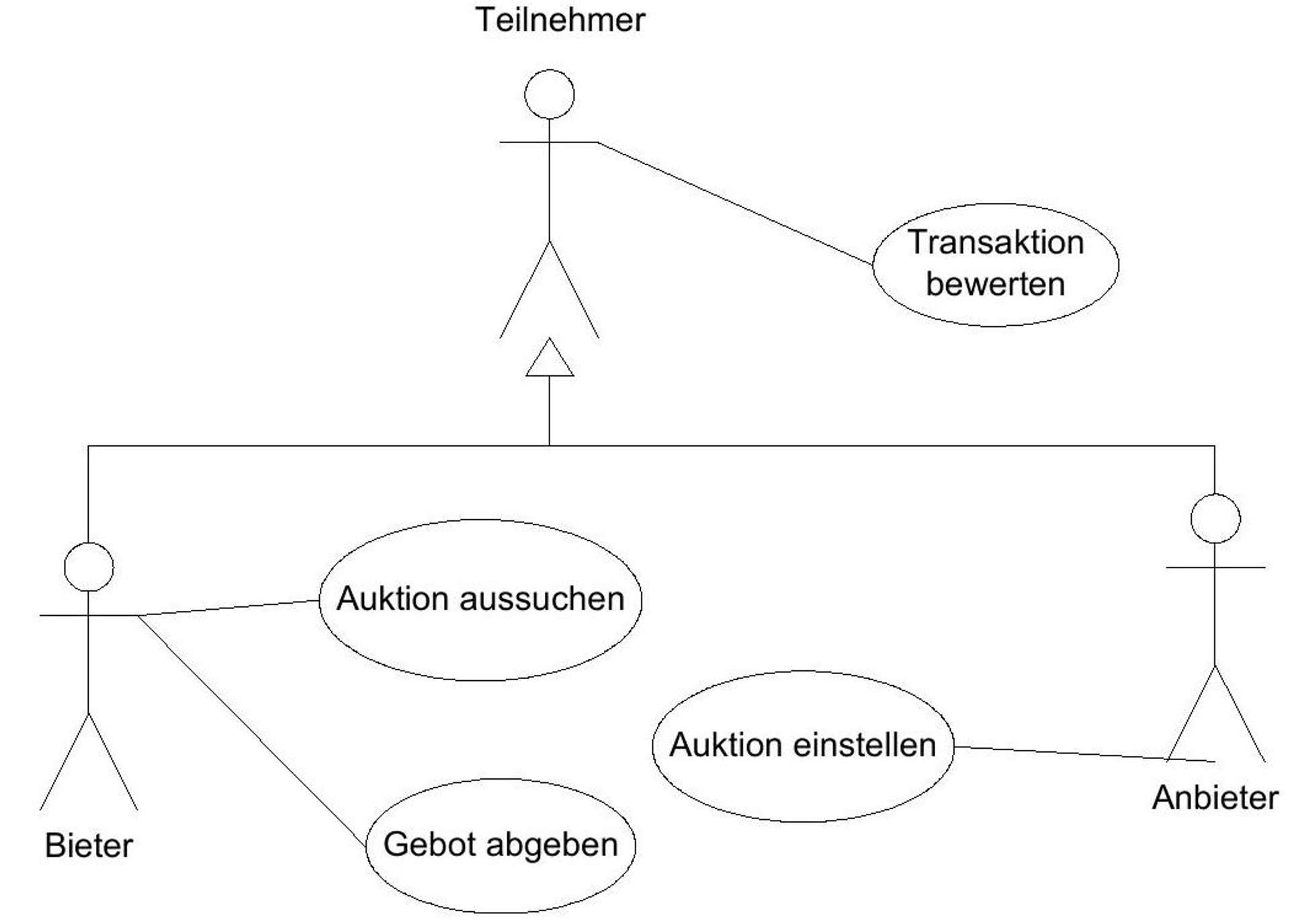
Selected use cases within the auction platform are considered in detail.^(31){ }^{31}
Figure 6: Selected use cases of the auction platform.
The participants are divided into bidders (also buyers) and sellers, whereby these are only temporary roles that each participant can also assume simultaneously for different auctions. A participant is already referred to as a bidder as soon as they intend to participate in an auction.
/Af 10/ Evaluate Transaction Actor: Bidder/Seller Precondition: Evaluable auction transaction has been executed. Postcondition: Transaction has been evaluated. Process Description: After a bidder has won an auction, the winner and seller are given the opportunity to evaluate it with a short text and the rating "positive", "negative", or "neutral".
/Af 20/ Create Auction Actor: Seller Precondition: Seller wants to auction goods. Postcondition: Auction can be found via the search function. Process Description: Seller defines the attributes of an auction via an input mask (see Figure 6).
/Af 30/ Select Auction Actor: Bidder Precondition: Bidder wants to bid on goods. Postcondition: Bidder has found an attractive auction or bidder has not found an attractive auction. Process Description: See turquoise colored functions in Figure 4.
/Af 40/ Submit Bid Actor: Bidder Precondition: Bidder wants to participate in an auction. Postcondition: Bidder has submitted a bid. If, in addition, the auction has ended and no further bid has been submitted after this one, the bidder is the winner of the auction. A purchase contract for the auctioned item is concluded between the winner and the seller of the auction. Exceptions: Bid could not be submitted because a higher bid has already been submitted in the meantime or the auction has ended. Process Description: See yellow colored function in Figure 4.
3.2 Implementation
3.2.1 Current Online Auction Platforms
As part of this thesis, an online auction platform based on P2P technology is designed. This contrasts with all current mainstream C2C auction platforms, represented in particular by eBay^(32){ }^{32}, which are implemented in a client-server architecture.
To better highlight the special characteristics of P2P technology, the technological basis as well as indirectly relevant aspects of eBay's business model will be briefly presented here.
3.2.1.1 Architecture
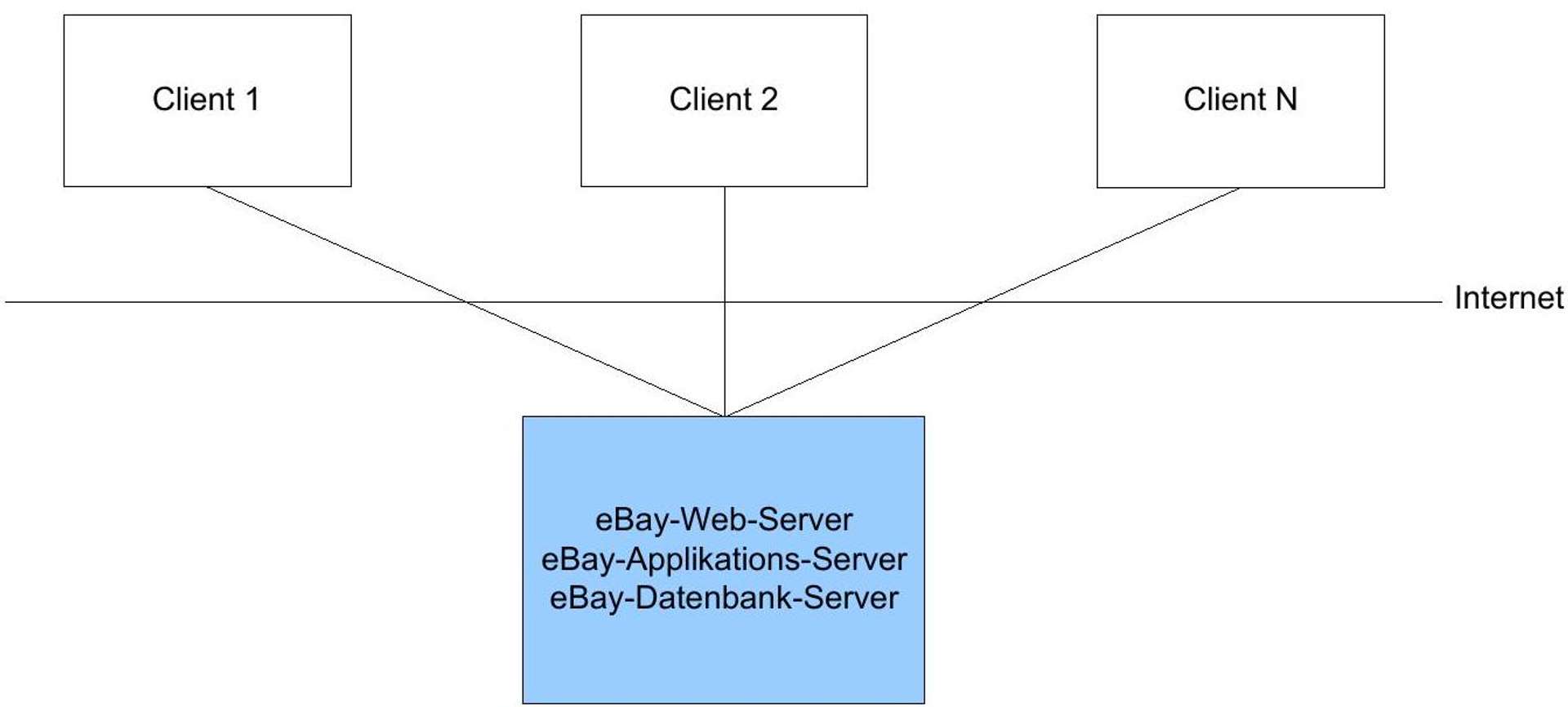
Figure 7: Client-server architecture of eBay.
The eBay auction platform is a classic web application.^(33){ }^{33}The object marked in blue in Figure 7 symbolizes the server. This may be composed of various computing units - logically, however, a single server is created on which all transactions run. The clients communicate with the server. Communication between clients at the eBay level does not take place.^(34){ }^{34}
3.2.1.2 Business Model
eBay's business model is based on fees being charged to the seller after a successful auction. On the cost side, eBay has to account for the operation of its application in addition to administration and marketing. In addition to the acquisition and maintenance of the server platform, eBay incurs costs due to usage-related traffic.
3.2.1.3 Reputation Model
As described in chapter 3.1.4 and /Anf 30/, users of an auction platform need to be able to assess the risk of a transaction. eBay uses a simple reputation model based on buyers and sellers being able to rate each other after a transaction has ended. The rating history is then available to future potential auction participants as a basis for decision-making.
3.2.2 Implementation Approach
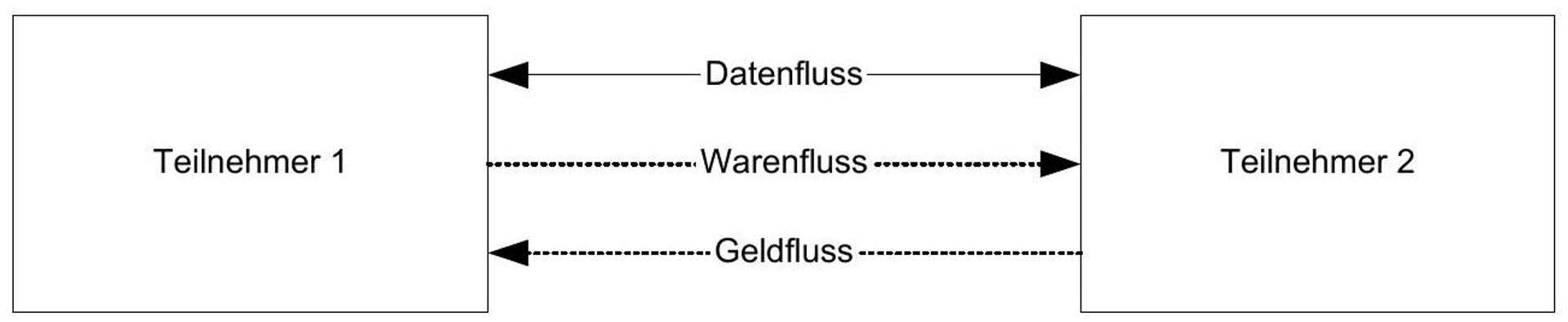
The architecture of the auction platform in the P2P network represents a natural mapping of the business process. Abstractly speaking, data, goods, and money flows follow the same path.
Figure 8: Data, goods, and money flows between participants in an auction.
The data flow runs directly between the participants in an auction via the P2P network. A detour via a third party, in particular the server of a service provider, is eliminated.
By eliminating the server, there is no central database where, for example, reputation data about the participants could be stored. Section 6.6 will show a method for calculating reputation without such a central database and how reputation can be used as an indicator of the risk of a transaction.
Another function of the server in auction platforms is the role of the arbitrator. Conflicts can arise during an auction if, for example, a seller claims to have received a bid, but the alleged bidder denies this. The auction platform in the P2P network must be able to resolve such conflicts as far as possible without the influence of third parties. Chapters 4 and 5 explain the approach to how such low-conflict self-administration is possible. The design of the auction platform is finally presented in Chapter 7.
4 Cryptography
Cryptography is the science of encrypting and obscuring information. The main goals of cryptography are:^(35){ }^{35}
Confidentiality (Secrecy) The goal of confidentiality is to transmit a message to a recipient without third parties learning about the transmission or even the content.
Data Integrity The goal of data integrity is to ensure that a message is not altered during transmission.
Authentication
Participant Authentication The goal of participant authentication is the unambiguous identification of a participant, whereby local identification is also considered here (e.g., to an ATM), so communication over an insecure channel does not necessarily have to be assumed.
Message Authentication (Non-repudiation, Attribution) The goal of message authentication is to prove the authorship of a document in order to be able to unambiguously determine the author and to prevent them from denying authorship. In daily life, this is usually guaranteed by signatures. Message authentication is thus the basis for many business transactions.
4.1 Symmetric Encryption
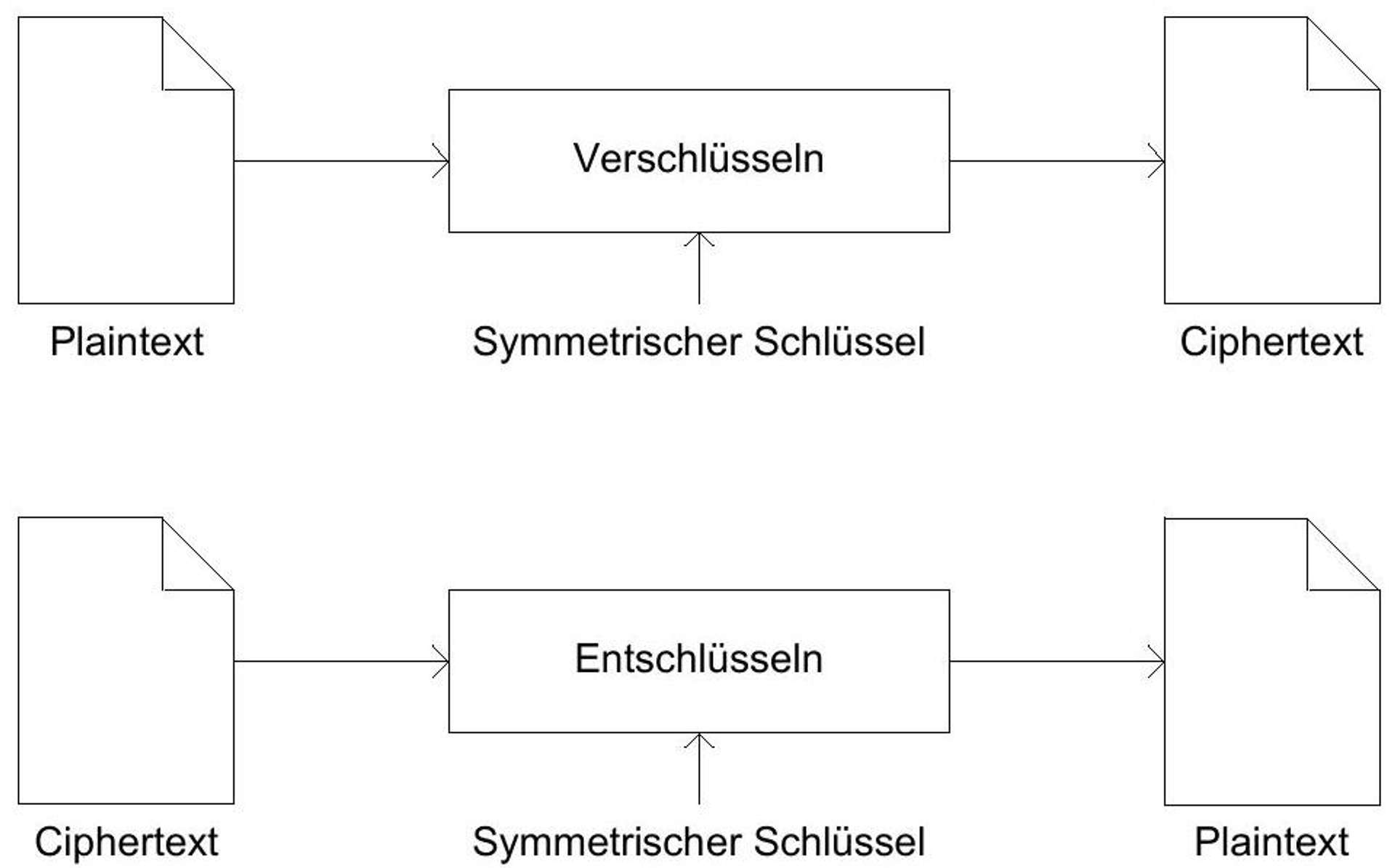
For millennia, attempts have been made to achieve these goals through the means of symmetric cryptography. Here, a message is transformed from plaintext to ciphertext using a key, whereby the same key (or a key easily derived from the key) is used to recover the plaintext from the ciphertext.^(36){ }^{36}
Figure 9: Encryption and decryption in a symmetric cryptosystem. After Fig. 2.1 in [Adams Lloyd 2002], p. 8.
The problem with this method is the necessity of exchanging the key between the participants in a message transmission. This exchange must take place over a secure channel, which is often difficult to implement, for example, when the participants are spatially distant from each other. An even bigger problem with symmetric cryptography, however, is the large number of keys. Each participant must have a key to every other participant with whom they want to communicate. With 1,000 participants, the number of keys can be in the range of half a million. In general, for nnusers, up to n^(2)//2n^{2} / 2keys will be needed, which also have a limited lifespan in all common encryption methods. Managing such quantities of keys therefore presents a significant bureaucratic challenge and can be described as impractical for many purposes.^(37){ }^{37}
4.2 Asymmetric Encryption
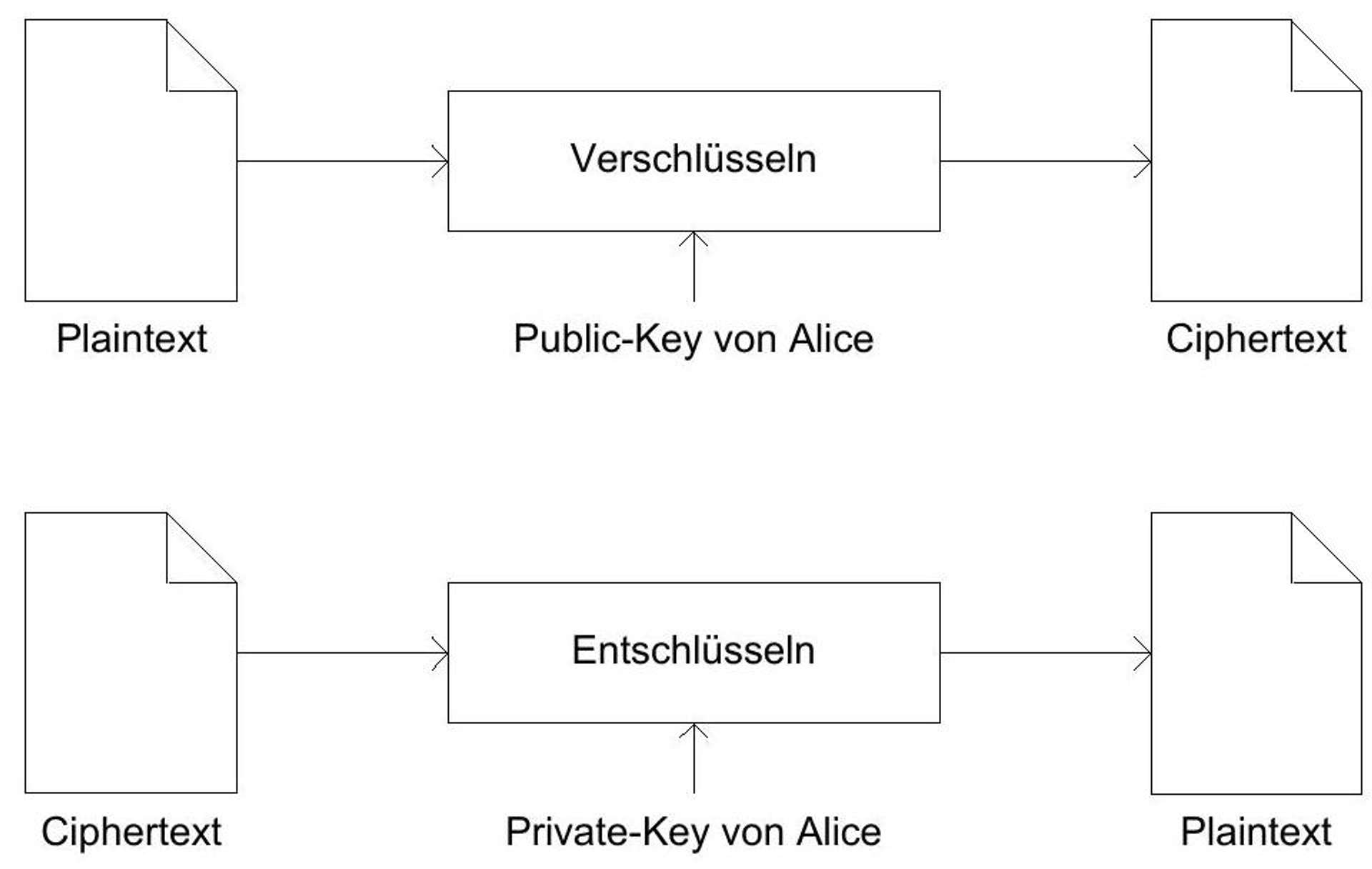
If two scientists, Whitfield Diffie and Martin Hellman, hadn't had a groundbreaking idea in 1976, the world would probably have taken a different path in the development towards the information society - with a mathematical trick, they solved the problem of key distribution described above. The fundamental question is: How can a message be sent to another participant without knowing a secret (the key in symmetric cryptography)? The answer given by Diffie and Hellman was to use a key pair instead of a single key, whereby one key - the public key - is publicly known and the other key - the private key - only needs to be known by its owner. Participant Bob can now send participant Alice a message by encrypting the message with Alice's public key. The message can now only be decrypted by Alice with her private key.^(38){ }^{38}
Figure 10: Bob sends Alice a message using public-key encryption.
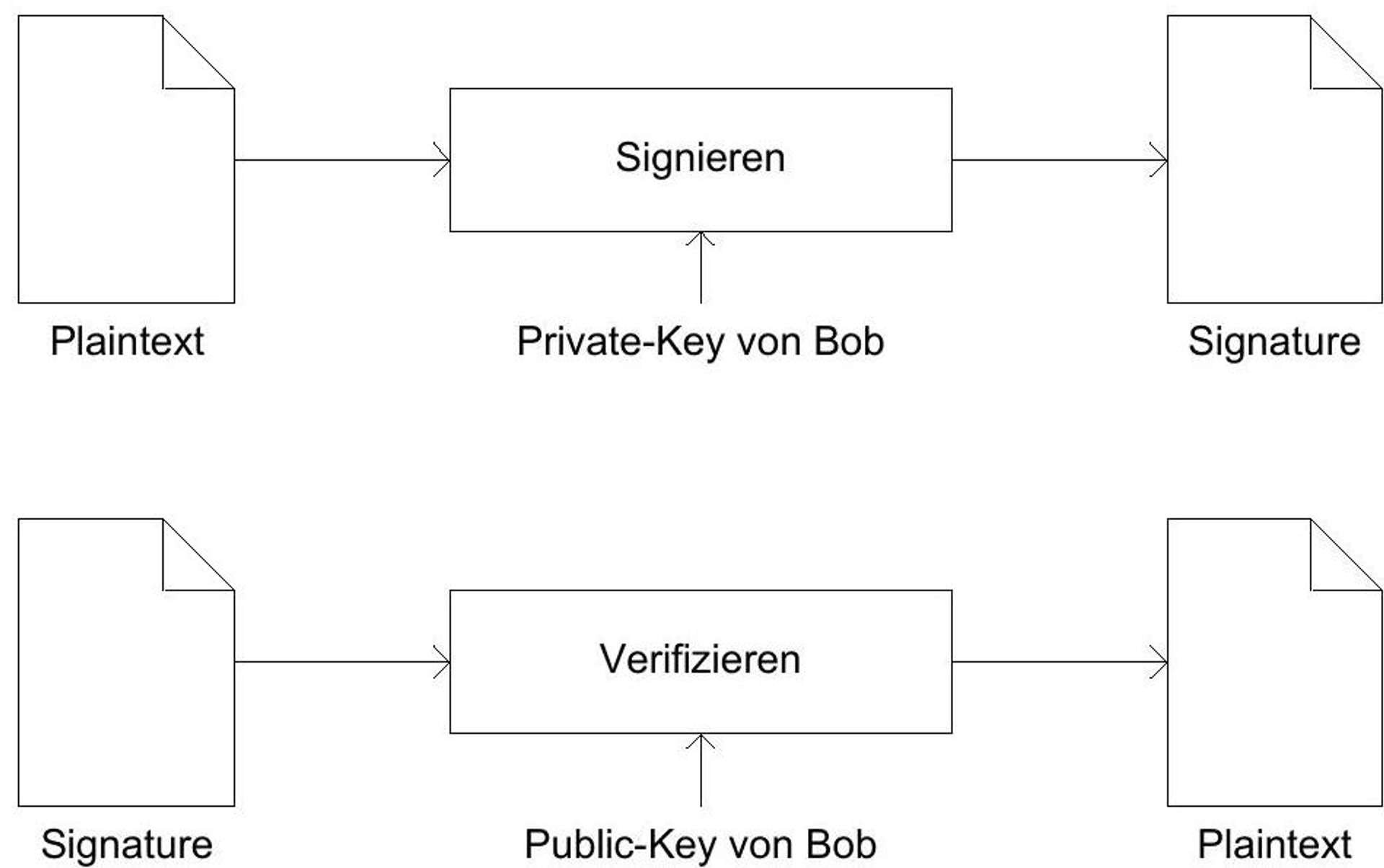
A so-to-speak "byproduct" of asymmetric cryptography is the possibility of a digital signature. If Bob encrypts a message with his own private key, a signature is created. This can be verified by decrypting the signature with Bob's public key and comparing it with the original text.^(39){ }^{39}In addition to the participant authentication guaranteed by the signature, it also guarantees the integrity of the data associated with it.
Figure 11: Bob signs a message. The signature is verified with Bob's public key.
Unfortunately, asymmetric cryptography also has a key distribution problem, albeit of a different kind than in symmetric encryption - the public key problem.
4.2.1 Public Key Problem
For Bob to send Alice an encrypted message, Bob must know Alice's public key, and for Alice to verify a signature from Bob, she must know Bob's public key. The problem now is: How do participants obtain the public key of another participant? A search on the Internet could provide many answers. The question is, which answer is correct - one, several, or none? The most obvious way to solve the problem is to exchange keys through personal contact. However, in the age of the Internet, this path is often impractical due to large spatial distances.
Various strategies have been developed to support the exchange of public keys, which are usually based on providing the keys with a certificate that proves their authenticity. The procedures differ mainly in the way these certificates are generated. Chapter 5 describes common procedures for issuing certificates. Chapter 7 will demonstrate that under certain conditions, the key distribution problem does not exist at all.
4.3 Cryptographic Hash Functions
Cryptographic hash functions are collision-free one-way functions that map messages of arbitrary length to a hash value of fixed length. This hash value serves as a fingerprint of the original message since it is assumed that no other message (and especially no other meaningful message) can be found that produces the same hash value. Similarly, it must not be possible to deduce the message from a hash value. Thus, it is possible to verify the knowledge of a shared secret between two participants without revealing the secret.^(40){ }^{40}
4.4 Notation
Public Key
Pub_(i)Pub_{i}is the public key of participant ii.
Private Key
Priv_(i)Priv_{i}is the private key of participant ii.
Electronic Signature
The electronic signature of a message mmfrom participant iiis sig_(i)(m)sig_{i}(m). In a tuple (e_(1),e_(2),dotse_(n),sig_(i))\left(e_{1}, e_{2}, \ldots e_{n}, sig_{i}\right), sig_(i)sig_{i}is the signature over the preceding elements.
Public Key Encryption
A message mmis encrypted with the public key of participant iiby crypt_(i)(m)crypt_{i}(m).
Cryptographic Hash Function
The cryptographic hash value of a message mmis hash(m)hash(m). In a tuple (e_(1),e_(2),dotse_(n),hash)\left(e_{1}, e_{2}, \ldots e_{n}, hash\right), hashhashis the hash value over the preceding elements.
Random Number Generator
The procedure rand()rand()returns a true random number with sufficient entropy^(41){ }^{41}.
5 Public Key Infrastructure
A Public Key Infrastructure (PKI) is the basis for a pervasive security infrastructure^(42){ }^{42}whose services are implemented using public key concepts and techniques.^(43){ }^{43}
The word infrastructure indicates that it is not the goal of a PKI to support a single application. Rather, the PKI offers an environment that allows various applications to operate within a security architecture. Instead of developing incompatible isolated solutions for specific applications, the PKI enables a consistent security landscape across application and even entire platform boundaries. The comparison with other infrastructures, such as the road or electricity network, is therefore not far-fetched. Accordingly, the security infrastructure must also meet similar, abstract requirements as the above networks:
The interface must be known and easy to use.
The results of using the infrastructure must be predictable and useful.
The way these results are generated does not need to be known to use the infrastructure.
For the user of the infrastructure, its existence should be largely transparent. This means that, apart from logging in and in exceptional cases (failure of the infrastructure), the user should not have to interact with the infrastructure in any way.
Probably the most important aspect of a security infrastructure is that it implements a single, trusted security technology that is available to the entire environment. Applications that use the services of the PKI can communicate and conduct transactions with each other undisturbed and securely.
5.1 Goals of PKI
Adams and Lloyd describe a PKI as an application enabler.^(44){ }^{44}The goal of the PKI is therefore to support applications. In a narrower sense, the PKI implements the goals of cryptography for its users in as transparent a manner as possible. However, it does not do this for its own sake. The real reason for implementing a PKI is the need to conduct transactions of any kind.
5.2 PKI Components and Services
A PKI provides a set of services and components to implement the security infrastructure. The extent to which and how each point is implemented naturally depends on the needs of the target group of the PKI.^(45){ }^{45}
5.2.1 Certificate
A certificate is the assurance by a third party that a given public key belongs to a given identity for a certain period. The certificate is signed with the private key of the third party.
5.2.2 Certification Authority
Certification Authorities (CAs) are designated participants in a PKI who confirm the authenticity of public keys through their signatures. Usually, there will be only a few CAs compared to the total number of participants. However, it is important that the public keys of the CAs are known to a large number (all) of participants for this model to work.
5.2.3 Certificate Repository
In addition to certified public keys, a PKI needs the ability to determine the public key for a given identity. The Certificate Repository^(46){ }^{46}serves this purpose.
5.2.4 Certificate Revocation
The statement expressed by a certificate - the binding between an identity and a key pair - can become false. This is especially the case when a private key is compromised. For these situations, there must be a way to revoke a certificate. This process is called Certificate Revocation.
5.2.5 Key Backup and Recovery
In a realistic scenario, users of the PKI will sooner or later lose access to their private key (e.g., due to a hard drive crash or forgetting a password). For these cases, options for backing up the key or another type of recovery should be created.
5.2.6 Automatic Key Update
Certificates usually have a limited lifespan. For such certificates, a PKI should provide an automatic way to update the certificate (and especially the key).
5.2.7 Key History
When certificates expire, there must still be a way to retrieve old keys for certain purposes (e.g., if a document was encrypted with an old key).
5.2.8 Cross-Certification
While it is conceivable that all certificates in a PKI refer to the same so-called root certificate, this scenario is unrealistic. Since this scenario is unrealistic, it will happen that two CAs certify each other. This process is called cross-certification.
5.2.9 Support for Non-Repudiation
Public key cryptography allows the signing of messages. A PKI must ensure that the binding between message and author given by a signature cannot be broken. In addition to the authorship of a document, this also guarantees the non-repudiation of receipt, delivery, and consent.
In fact, the electronic signature only means that a specific private key was used. The transitive conclusion to the owner of the private key is not beyond any doubt (e.g., in case of key theft). A PKI can therefore only provide support. In case of doubt, a judge is still needed to evaluate the evidence.
Non-repudiation plays a particularly important role in PKI services. The ability to prove the occurrence of a transaction, as well as the identity and consent of the participants afterwards, is essential for the handling of complex business processes over a network.
5.2.10 Time Stamping
It is especially important for ensuring non-repudiation that there is a secure source for time within the PKI, because due to the limited validity of the certificates and the possibility of revocation, it must be possible to subsequently verify whether a signature was made at a time when the key was still valid.
5.2.11 Client Software
Some form of client software will always be necessary for implementing a PKI. However, its scope depends on the respective system.
5.3 Trust Models
If the assignment of public keys to identities takes place via certificates, the question remains how trustworthy the certificate itself is. If any participant acts as a CA, the certificate is practically worthless. Rather, the certificate must represent a gain in trust - in other words, the CA must be more trustworthy than the certified party.
5.3.1 Strict Hierarchy of Certification Authorities
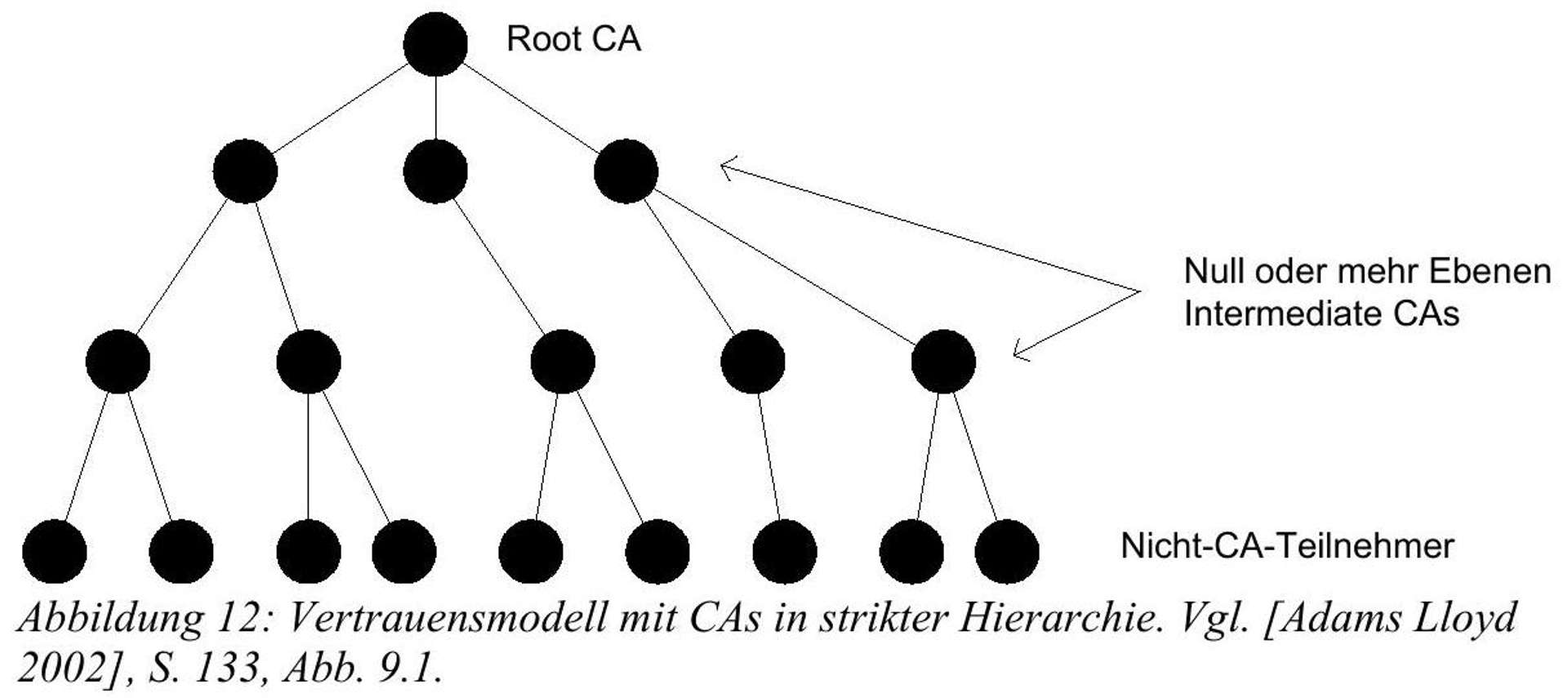
In a strict hierarchy of Certification Authorities, there is a Root CA from which all trust in the PKI originates. This means that all participants must trust the Root CA. The Root CA's certificate is self-signed.^(47){ }^{47}There can be further levels of CAs below the Root CA, whose certificates are signed by a CA at the respective higher level. The leaves of the resulting tree are the actual participants in the PKI. Valid participant certificates refer to the Root CA via the certificate chain by tracing the respective CAs.^(48){ }^{48}
Figure 12: Strict hierarchy of CAs.
All processes performed by a CA are associated with bureaucratic effort. When issuing a certificate, the identity of the certificate holder must be established beyond doubt, which is usually done by means of hand-signed documents transmitted by mail or fax. This procedure must be repeated for any changes to the certificate. Issuing a certificate is therefore usually associated with costs^(49){ }^{49}.
5.3.1.1 Architecture with Distributed Trust
The introduction of a strict hierarchy for all CAs in all PKIs of this world is unrealistic. Distributed trust provides a remedy. Here, several inherently strict hierarchies exist in parallel, whose respective Root CAs cross-certify each other (cross-certification).^(50){ }^{50}
5.3.2 Web of Trust
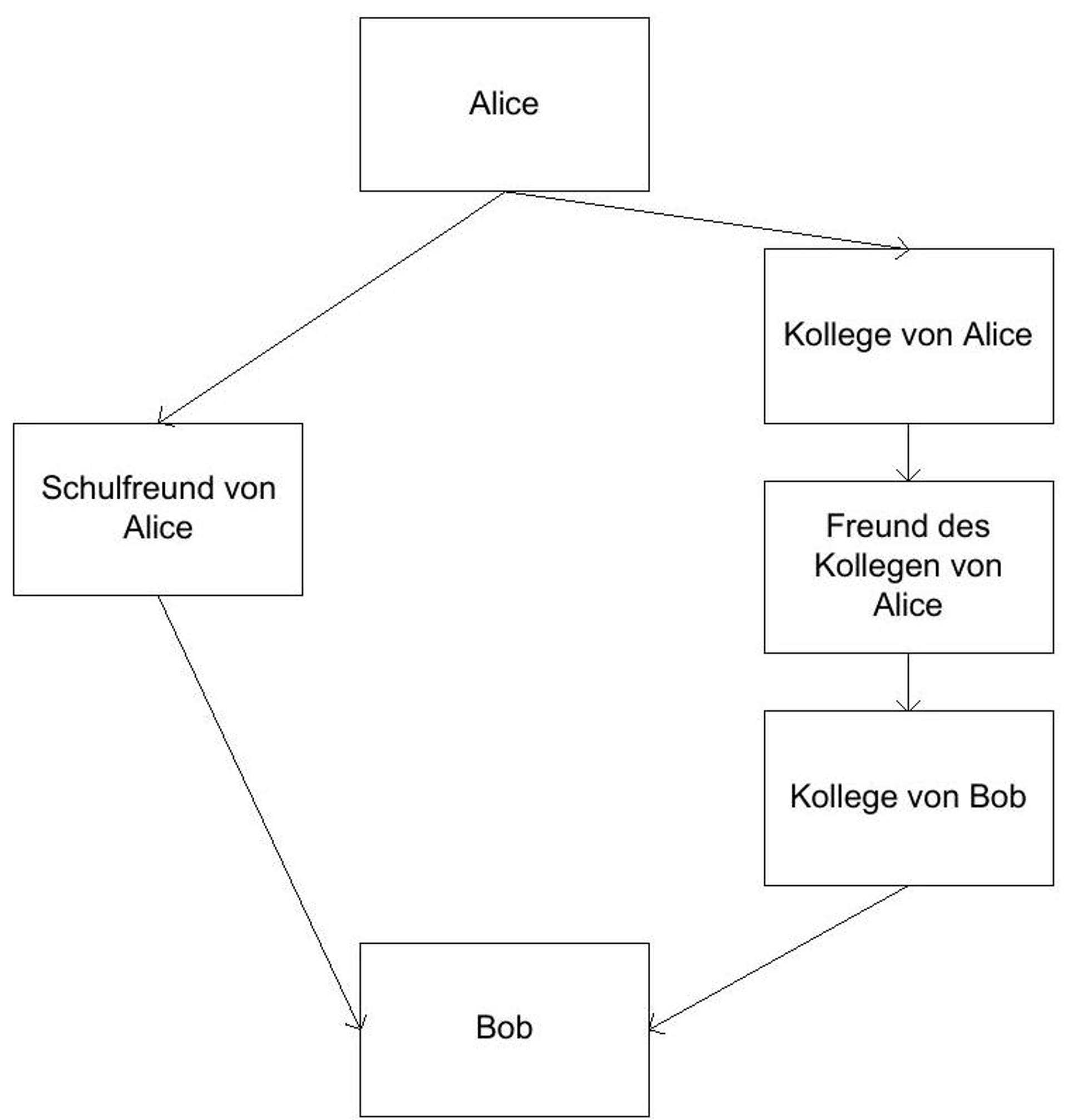
The Web of Trust, developed for PGP^(51){ }^{51}, attempts to manage the certification of public keys without the use of dedicated CAs. The approach assumes that each participant can certify the identity and public keys of a set of other participants.^(52){ }^{52}This set is called friends. If Alice wants to write an email to Bob, but cannot verify Bob's public key herself, she looks at the set of keys that her friends certify, and so on. This way, she will hopefully find one or more certificate paths to Bob.^(53){ }^{53}The shorter the path and the more redundant the route, the more certain the validity of Bob's key. The assessment of validity is now up to Alice herself and is therefore not to be mastered without technical understanding.^(54){ }^{54}
Figure 13: The certification path from Alice to Bob, according to [Feisthammel 2002].
The Web of Trust is a first approach to using the existing trust in a network to solve the public key problem. Chapter 6 will therefore deal more intensively with the concept of trust.
6 Trust
This thesis has so far dealt with trust in two different places: in Chapter 3.1.4 regarding the risk of a transaction and in Chapter 5.3 regarding the legitimacy of a public key. In the first case, trust refers directly to a participant; in the second case, the trustworthiness of a particular CA is examined. However, the underlying meaning of the term is the same:
Trust is the subjective expectation of a person regarding the future behavior of another person, based on previous encounters^(55){ }^{55}between these persons.^(56){ }^{56}
Trust is of central importance for the efficient execution of business processes, as it allows the protagonists to make spontaneous decisions. In an environment without a basis of trust, on the other hand, a lot of time is wasted taking precautions to prevent possible misconduct by business partners. Distrust, in turn, has a similarly positive effect as trust itself, as it also helps to make conscious decisions about cooperating with others.^(57){ }^{57}
In the online auction scenario, the business partners are completely unknown to each other.^(58){ }^{58}The existence of a direct trust relationship can therefore be excluded. However, since auctions take place within a limited time frame, efficient execution is essential. For the success of the auction platform, it is therefore of utmost importance to support the participants in building trust.
6.1 Transitive Trust
Transitive trust expresses that individuals have a certain basis of trust with individuals who are within the trust circle of their trusted contacts.^(59){ }^{59}This is how the so-called Web of Trust^(60){ }^{60}is formed.
Figure 14: Visualization of the trust relationship between Bob, Alice and Christian.
Figure 14 visualizes the trust relationship between Alice, Bob, and Christian. The transitive trust between Alice and Christian arises through Bob, who has a relationship with both. The strength of the transitive trust depends on many factors and will not be discussed further here. However, it can be assumed that transitive trust is usually weaker than, and at most identical to, a direct trust relationship.
6.2 Small-World Networks
In 1967, psychologist Stanley Milgram conducted an experiment with an astonishing result. The approach was that various people within the USA should send a letter to another, completely unknown person living in a distant part of the USA. Instead of sending it directly, however, the letter could only be sent to personal friends. The number of steps a letter needed to reach its destination was then examined. The surprising result was that the letters needed an average of only 6 steps to reach their destination - the small-world phenomenon^(61){ }^{61}was born.^(62){ }^{62}
The reason for the small number of steps between any two people is that people live in a social network and these networks are small. A social network can practically only have two states. Either all people live in small, isolated communities with no connections to each other, or they live in a single large group where everyone is connected to everyone else through a few steps. There is no middle ground, e.g., given by a few large groups that are self-contained. This is surprising insofar as people traditionally think in categories such as social classes or races, which, however, do not seem to have a dramatic influence on the connection distance between any two people in the network.
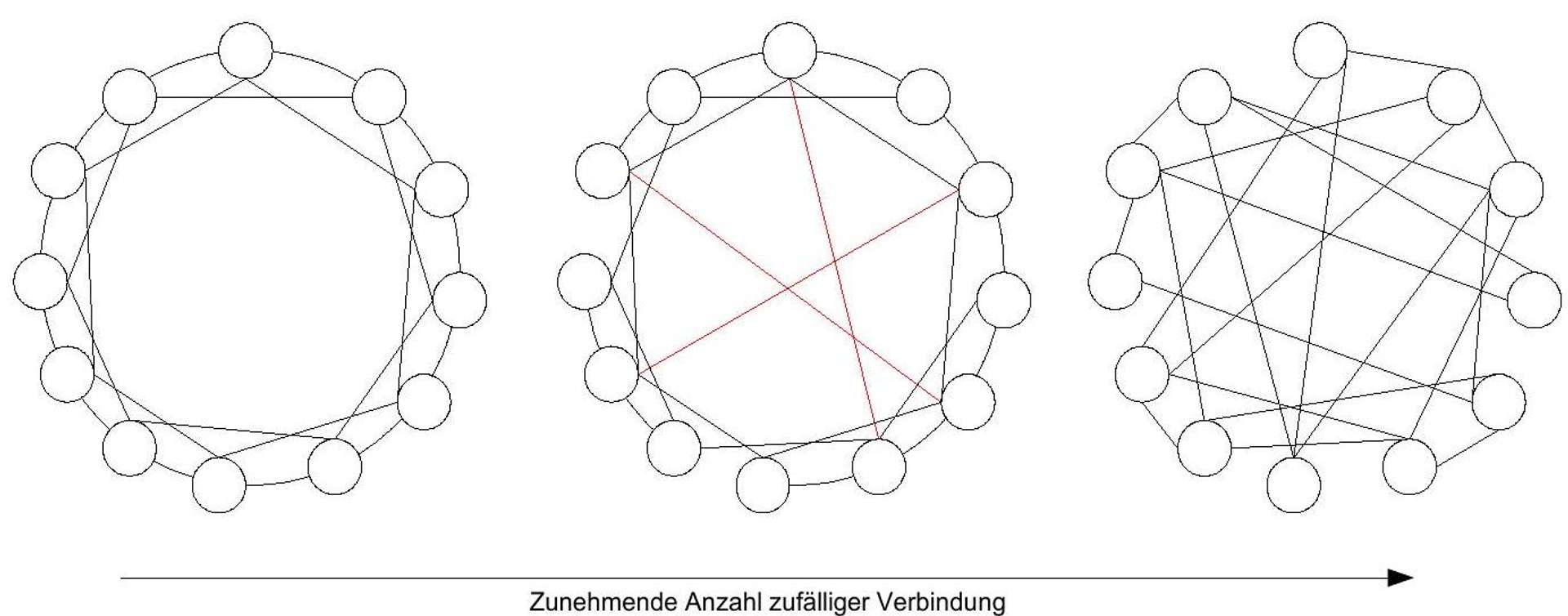
Figure 15: Graphs with ordered and random connections. Based on [Watts 2003], p. 87, Fig. 3.6.
To understand the origin of the small attribute of a network, it helps to consider three types of graphs. The left graph in Figure 15 shows a completely ordered network. The distance between two opposite nodes is thus quite large. In the right graph, the edges between the nodes are chosen randomly. For such random graphs, it has been proven that connectivity is high as soon as more than one edge per node occurs^(63){ }^{63}- if they were an accurate abstraction of reality, they would explain the small-world phenomenon. However, since social relationships do not develop purely randomly (the probability of someone from Hamburg knowing someone else from Hamburg is significantly higher than knowing a native of the Brazilian rainforest), this model is not realistic.
The middle graph, on the other hand, shows a representation that could well serve as a model of a social network. Each node is part of a closely connected group. However, there are also individual edges that connect distant nodes. These "shortcuts" have a dramatic effect on the average distance between two nodes in the network and are the key to the small-world phenomenon. In a social network, it is indeed the case that people tend to interact with a group that is closely intertwined. However, individuals are always active in several such groups. These people form the "shortcuts" in the middle graph.^(64){ }^{64}
A small-world network combines local group formation and globally short connections. The consequence is that from the subjective perspective of a single node, the small characteristic never becomes apparent because it can only overview its immediate surroundings. Only a global view reveals the true degree of networking.
6.2.1 Trust in Small-World Networks
Chapter 6.1 describes how a Web of Trust can be built using transitive trust. A kind of chain of trust is established between any two participants. If the underlying network is small, then it can be assumed that this chain will always be relatively short, regardless of the number of nodes in the network. In other words, every participant in the P2P network has a transitive trust relationship with every other participant, which runs through a relatively short trust chain.^(65){ }^{65}From this, it can be concluded that a certain basis of trust exists in the network, even if no participant can subjectively perceive this. However, it shows that there is potential that could be exploited by special algorithms.
Technically, with regard to small-world networks, it remains questionable whether it is possible to find these short paths with reasonable effort. However, it will be shown later that a sufficient assessment of a person's trustworthiness can also be made without explicitly finding the short paths.
6.3 Trust Relationships
Trust relationships between two people can be very diverse. This paper limits its consideration to the states: trust, distrust, and no relationship.
6.4 Trust Metrics
Trust metrics are computational models that provide a quantitative assessment of the trust that one person should have in another. Trust metrics are inherently backward-looking in their consideration. Therefore, they cannot predict sudden changes in human behavior.
A simple trust metric would, for example, traverse the trust chain between two participants and return the lowest trust rating. However, there are many other techniques, a complete review of which is beyond the scope of this thesis. More complex trust metrics must take social and psychological aspects of trust into account while remaining scalable.^(66){ }^{66}
6.4.1 Use in P2P Networks
Trust metrics for use in P2P networks must meet special requirements:^(67){ }^{67} /Ver 10/ The system must be completely self-regulating. Correct behavior within the network must be enforced by the participants themselves, as there is no central authority. /Ver 20/ The system must guarantee anonymity for users. Trust must be mapped to identifiers that have no externally associable meaning.^(68){ }^{68} /Ver 30/ New participants in the network should not enjoy an advantage. This prevents malicious participants from gaining an advantage by frequently changing their identity. /Ver 40/ The overhead in terms of computation, infrastructure, storage space, and message complexity should be minimal. /Ver 50/ The system must also be robust against collectives of malicious users. /Ver 60/ For use in decentralized P2P networks, the calculation must be able to be performed distributedly.
6.5 Global Trust
The definition used in this paper primarily considers trust as a local phenomenon. However, global trust, which takes a different perspective, is also useful. Global trust maps the aggregated trust of an entire network onto a single participant. The algorithms are usually based on Google's^(69){ }^{69}PageRank^(70){ }^{70}algorithm for evaluating internet pages. PageRank calculates the importance of a page based on the importance of the pages that link to it. The same concept can be applied to trust - trust statements from people who are trusted by more people are worth relatively more. The recursive nature of these models automatically leads to a complete consideration of the underlying network. Trust metrics that use a global concept of trust have the advantage that they also work without an efficient algorithm for finding local transitive trust relationships, the short paths in the underlying small-world network.
6.6 EigenTrust
An algorithm for calculating the global trust or reputation of participants in a P2P network is the EigenTrust algorithm. EigenTrust is demonstrated in [Kamvar Schlosser Garcia-Molina 2003] using the example of a file-sharing network in which the problem of participants distributing no or fake files is to be minimized. Here, EigenTrust is applied to the online auction scenario.^(71){ }^{71}
Let QQbe the set of participants in the network. The winner and the seller of an auction are given the opportunity to evaluate each other after the auction has ended. The local reputation (history of previous auctions) between participants i in Qi \in Qand j in Qj \in Qis defined as follows:
Other participant jjbehaved positively towards iiin an auction: (tr(i,j)=1)(tr(i, j) = 1). This is the case, for example, if an auction winner paid promptly and in full.
Other participant jjbehaved negatively towards iiin an auction: (tr(i,j)=-1)(tr(i, j) = -1). This is the case, for example, if the auctioneer does not deliver after the auction.
All participants trust themselves: (tr(i,i)=1)(tr(i, i) = 1).
The local trust value from iito jjis s_(ij)=sum tr_(ij)s_{ij} = \sum tr_{ij}.
EigenTrust now determines the global reputation of a participant iifrom the local trust of other participants towards iiand their global trust.
6.6.1 Normalization of Local Trust Values
Local trust values must be normalized to be aggregated securely, as otherwise the system could be circumvented by assigning arbitrarily high trust values. The normalized local trust value is defined as:
The term max(s_(ij),0)\max(s_{ij}, 0)sets all negative s_(ij)s_{ij}to 0. This facilitates normalization but has the consequence that the distinction between a bad relationship and no relationship between two participants is lost.^(72){ }^{72}The value c_(ij)c_{ij}is always between 0 and 1.
6.6.2 Aggregation of Local Trust Values
It is now necessary to aggregate the local trust values. To do this, participant iiasks all their acquaintances jjabout their opinion of kk. The statements of the acquaintances are in turn weighted by the trust of iiin them.
t_(ik)t_{ik}now expresses the trust of iiin kk, taking into account one level of transitive trust relationships. Note that the formula is not recursive.
The above formula can be represented in matrix notation: Let
CCbe the matrix c_(ij)c_{ij},
vec(t)_(i)\vec{t}_{i}be the vector t_(ij)t_{ij},
vec(c)_(i)\vec{c}_{i}be the vector of local normalized trust values of ii, then:
By repeatedly multiplying the matrix C^(T)C^{T}by itself, the number of transitive relationship levels considered is increased. Through a sufficiently large number of repetitions, iigains a complete overview of the network.
In doing so, vec(t)_(i)\vec{t}_{i}converges for all iito the same vector^(73){ }^{73}vec(t)\vec{t}, the global trust vector of the network.
6.6.3 Probabilistic Interpretation
Since EigenTrust is based on PageRank^(74){ }^{74}, the trust values can be interpreted as probabilities similar to the Random Surfer Model. The Random Surfer Model considers an idealized web surfer who randomly clicks on links and thus moves through the WWW. After a certain number of clicks, the probability is higher that the random surfer has arrived at a page that many links point to than at a page that fewer links point to. The Google search engine uses this probability as an indicator of the quality of a website.
Figure 16: The trust network of participants a to f. The edge label is the respective normalized local trust value between the connected participants.
The random surfer in an EigenTrust network moves from participant to participant. If they are at participant ii, they jump to participant jjwith probability c_(ij)c_{ij}. After the random surfer has moved like this for a while, they are more likely to be at a trustworthy participant than at an untrustworthy participant. The global trust vector vec(t)\vec{t}is the stationary distribution of the Markov chain defined by CC.
6.6.4 Simplified EigenTrust Algorithm
Apparently vec(t)\vec{t}converges to the same vector for all vec(c)_(i)\vec{c}_{i}. We therefore choose the same vector vec(e)\vec{e}for all ii, whose values are each (1//"number of participants")(1 / \text{number of participants}), i.e., a uniform probability distribution.
From this, a simple version of the EigenTrust algorithm can be derived, which assumes that a central location knows all the values of the matrix CC.
delta\deltais assigned the length of the vector resulting from the subtraction of the vector vec(t)\vec{t}from the last iteration from the vector vec(t)\vec{t}of the current iteration. The algorithm terminates when this length (i.e., the gain in accuracy through one iteration) becomes smaller than a given value epsilon\epsilon.
6.6.4.1 Refinement
To be used in a real-world scenario, the algorithm needs to be extended by three aspects.
There will usually be a set of pre-trusted participants^(75){ }^{75}in a network. As will be shown later, there are several advantages for the EigenTrust algorithm if this set is taken into account. Mathematically, this can be represented by replacing the vector vec(e)\vec{e}with a distribution vec(p)\vec{p}that has the following properties:
Let PPbe the set of pre-trusted participants.
p_(i)=1//|P|p_{i} = 1 / |P|if i in Pi \in P, otherwise
p_(i)=0p_{i} = 0
In vec(t)=(C^(T))^(n) vec(p)\vec{t} = (C^{T})^{n} \vec{p}, all trust originates from pre-trusted participants. The algorithm will thus converge faster in the presence of malicious collectives that rate each other positively, since the collectives are only considered in later iterations.
There will always be inactive participants (e.g., new participants) who do not trust anyone or do not even know anyone. It is defined for these participants that they trust the pre-trusted participants PP.^(76){ }^{76}This results in the following redefinition for the matrix CC:
To minimize the risk of subversion of the algorithm by malicious collectives (groups of participants who rate each other very well but give bad ratings to outsiders), an additional extension is necessary: Let aabe a constant between 0 and 1.
The new line 5 prevents the trust in truly trustworthy participants from ever becoming so small that the algorithm gets stuck in a collective. Otherwise, the risk would be that all trust outside the collective would become vanishingly small compared to the malicious participants. This shows that it must be avoided under all circumstances that a participant from PPbecomes part of a malicious collective. The number of participants in PPshould therefore be reduced to a minimum.
6.6.4.2 Convergence
The EigenTrust algorithm generally converges quickly. Simulations have shown that delta\deltano longer changes significantly after fewer than 10 iterations.
A proof of the convergence of the EigenTrust algorithm will not be provided here. However, it should be noted that all values in C^(T)C^{T}are less than or equal to 1 and greater than or equal to 0. It is therefore intuitive that the length of the vector (C^(T))^(k) vec(t)(C^{T})^{k} \vec{t}decreases with increasing kkand that this decrease slows down. A detailed consideration of the convergence of PageRank, which can be transferred to EigenTrust, is given in [Haveliwala Kamvar 2003].
6.6.5 Distributed EigenTrust Algorithm
The distributed EigenTrust algorithm is also initially presented in a simplified version. For all participants ii, it is assumed that they know both their normalized local trust vector vec(c)_(i)\vec{c}_{i}and their own global trust value t_(i)t_{i}. Other participants can therefore learn t_(i)t_{i}by asking ii.
For the distributed algorithm, the assumption that CCis completely known to the computer is dropped. Instead, all participants collaborate to calculate the c_(ij)c_{ij}. To visualize the calculation process, it is helpful to imagine a kind of chess game with an arbitrary number of players. The game is divided into rounds, and in each round, each player performs a calculation whose result they pass on to a set of other players. The data a player receives at the end of each round forms the basis for the calculations of the next round. A distributed algorithm is only usable in practice if the number and size of messages transmitted between participants do not overload the network. The approach to distributing EigenTrust is to break down the term (1-a)C^(T) vec(t^((k)))+a vec(p)(1-a) C^{T} \vec{t^{(k)}} + a \vec{p}into its component notation: (1-a)(c_(1i)t_(1)^((k))+dots+c_(ni)t_(n)^((k)))+ap_(i)(1-a) (c_{1i} t_{1}^{(k)} + \ldots + c_{ni} t_{n}^{(k)}) + a p_{i}. It must now be ensured that iiknows the values of c_(ni)c_{ni}and t_(n)^((k))t_{n}^{(k)}for all nnand kkor knows that one of them is 0. A property of the distributed algorithm is that only the pre-trusted participants need to know their value for p_(i)p_{i}. They therefore remain anonymous.
Definitions:^(78){ }^{78}
A_(i)A_{i}: Set of participants who have made a trust statement about ii.^(79){ }^{79}
B_(i)B_{i}: Set of participants about whom iihas made a trust statement.
Theorem 1:
If j inA_(i)j \in A_{i}, then i inB_(j)i \in B_{j}or j inA_(i)=>i inB_(j)j \in A_{i} \Rightarrow i \in B_{j}. Proof by reflection: If jjhas made a trust statement about ii, then jjhas made a trust statement about ii.
Function Definitions:
Let kkbe the round index and a,b,ca, b, cbe participant indices.
step(k,a,b)=c_(ab)t_(a)^(k)step(k, a, b) = c_{ab} t_{a}^{k}
Let kkbe the round index and iibe the participant index.
compute_round(k,i)=(1-a)(step(k,1,i)+step(k,2,i)+dots+step(k,n,i))+ap_(i)compute\_round(k, i) = (1-a) (step(k, 1, i) + step(k, 2, i) + \ldots + step(k, n, i)) + a p_{i}
Let t_(i)^((a))t_{i}^{(a)}be global variables for a=ka = kand a=k+1a = k+1.
Each participant iicalculates: 1: k=0k = 0; 2: Ask all participants j inA_(i)j \in A_{i}for t_(j)^((0))=p_(j)t_{j}^{(0)} = p_{j}; 3: repeat 4: quadt_(i)^((k+1))=compute_round(k,i)\quad t_{i}^{(k+1)} = compute\_round(k, i); 5: quad\quadSend step(k+1,i,j)step(k+1, i, j)to participants j inB_(i)j \in B_{i}; 6: quad\quadWait for the receipt of step(k+1,j,i)step(k+1, j, i)from j inA_(i)j \in A_{i}; 7: until distance() < epsilondistance() < \epsilon;
Execution:
The following is an example execution of the EigenTrust algorithm in a network consisting of two participants iiand jj.
Round 0 iican calculate compute_round(0,i)compute\_round(0, i)because it can calculate step(0,j,i)step(0, j, i). iican calculate step(0,j,i)step(0, j, i)because it knows c_(ji)c_{ji}and has requested t_(j)^((0))t_{j}^{(0)}. iisends step(1,i,j)step(1, i, j)to j inB_(i)j \in B_{i}. iican calculate step(1,i,j)step(1, i, j)because it knows c_(ij)c_{ij}and t_(i)^((1))=compute_round(0,i)t_{i}^{(1)} = compute\_round(0, i).
Round 1 iican calculate compute_round(1,i)compute\_round(1, i)because j inA_(i)j \in A_{i}sends step(1,j,i)step(1, j, i). j inA_(i)j \in A_{i}can send iistep(1,j,i)step(1, j, i)because it calculated this value in round 0. iisends step(2,i,j)step(2, i, j)to j inB_(i)j \in B_{i}. iican calculate step(2,i,j)step(2, i, j)because it knows c_(ij)c_{ij}and t_(i)^((2))=compute_round(1,i)t_{i}^{(2)} = compute\_round(1, i).
Round 2 iican calculate compute_round(2,i)compute\_round(2, i)because j inA_(i)j \in A_{i}sends step(2,j,i)step(2, j, i). j inA_(i)j \in A_{i}can send iistep(2,j,i)step(2, j, i)because it calculated this value in round 1. iisends step(3,i,j)step(3, i, j)to j inB_(i)j \in B_{i}. iican calculate step(3,i,j)step(3, i, j)because it knows c_(ij)c_{ij}and t_(i)^((3))=compute_round(2,i)t_{i}^{(3)} = compute\_round(2, i).
Round kk iican calculate compute_round(k,i)compute\_round(k, i)because j inA_(i)j \in A_{i}sends step(k,j,i)step(k, j, i). j inA_(i)j \in A_{i}can send iistep(k,j,i)step(k, j, i)because it calculated this value in round (k-1)(k-1). iisends step(k+1,i,j)step(k+1, i, j)to j inB_(i)j \in B_{i}. iican calculate step(k+1,i,j)step(k+1, i, j)because it knows c_(ij)c_{ij}and t_(i)^((k+1))=compute_round(k,i)t_{i}^{(k+1)} = compute\_round(k, i).
From the presentation of the execution of the distributed algorithm, it should be clear that the execution is possible because the participants, in cooperation, can calculate all the necessary values.
6.6.6 Distributed Hash Tables
An important building block for securing the distributed EigenTrust algorithm (although its usefulness is not limited to this) is distributed hash tables (DHTs). DHTs, like normal hash tables, have two basic functions. A value can be stored for a key, and this value can be retrieved again using the key. The storage of keys and values is distributed across the computers of a network. Ordinary hashing algorithms are used on the individual computers to store the data. The actual core of DHT algorithms is a routing algorithm that finds the computer(s) on which the associated value can be found for a given key. A good DHT achieves a runtime of O(log n)O(\log n)for nnparticipants. Due to the volatile nature of P2P networks, DHTs must be prepared for the network constantly being expanded with new participants and for participants constantly leaving the network.^(80){ }^{80}
Common DHT algorithms are Content Addressable Network (CAN)^(81){ }^{81}, Chord^(82){ }^{82}, and Kademlia^(83){ }^{83}. To illustrate how a DHT works, the algorithm underlying a CAN will be presented here as an example. A CAN is a dd-dimensional space, whereby the algorithm also works in two-dimensional space, which will be used here for a more understandable presentation.
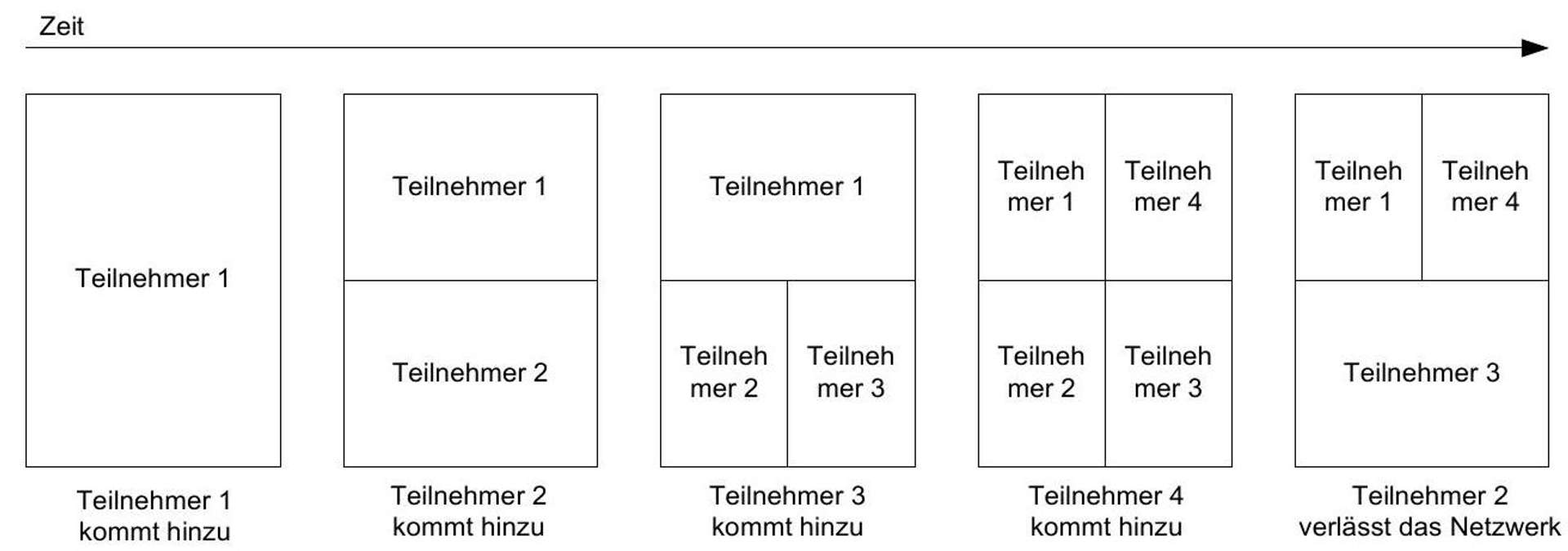
Figure 17: The partitioning of a two-dimensional space in the CAN network over time (Cf. [Ratnasamy Francis 2001], p. 3, Figures 2 and 3).
A CAN initially has one participant to whom the entire coordinate system is assigned. When another participant joins, the coordinate system is distributed among the participants. Each further participant that joins again divides a piece of space with another participant (see Figure 17, states 1-4 [from left]). If a participant leaves the network, the space assigned to them falls to a neighbor (see Figure 17, state 5). Note that due to the way the space is divided, a participant knows their neighbors in the space, whereby the neighbors are those participants whose space overlaps in at least one dimension and does not overlap in at least one dimension. The CAN hash function maps keys to points in the coordinate system. To find the participant to whom the space is assigned in which a certain point lies, a participant sends a request to the neighbor who is closest to the target point. This neighbor forwards the request in the same way until the destination is reached. This routing algorithm achieves a runtime of O(n^(1//d))O(n^{1/d}), which corresponds to a runtime of O(log n)O(\log n)for d=(log_(2)n)//2d = (\log_{2} n) / 2.^(84){ }^{84}
6.6.7 Secure EigenTrust Algorithm
In the distributed EigenTrust algorithm as presented so far, all participants are responsible for providing their own global trust value. This procedure carries the security risk that participants could lie about this value to subvert the system. The security vulnerability can be circumvented by delegating responsibility for calculating the global trust value to another participant. However, the problem remains that a malicious participant could decide to always provide false values when asked to calculate a value.
As a countermeasure, the trust value is therefore calculated by multiple participants.
Each participant iiis assigned a set of participants M_(i)M_{i}of fixed size mm, who calculate the global trust value of ii. These participants are called Score Managers. The calculation is performed redundantly by all participants in M_(i)M_{i}, whose results are then combined by a majority decision so that the probability that a malicious participant or a malicious collective can influence the trust value is minimized. The participants that a Score Manager evaluates are called daughters.
To implement the described security measures, the algorithm must meet the following requirements:^(85){ }^{85} /Sec 20/ Randomization. A participant must not be able to influence whose trust value they calculate, for example, to calculate their own value. /Sec 30/ Redundancy. Each calculation must be performed by multiple independent participants.
One way to meet these requirements is to use a distributed hash table (see Section 6.6.6). DHTs map inputs into a virtual space, where the coordinates in this space are assigned to the participants in the P2P network. The randomization (/Sec 20/) should be a property of the chosen DHT so that a participant cannot choose where in the DHT space they are located. A participant iiforms M_(i)M_{i}by hashing their identifier with mmdifferent cryptographically secure DHT algorithms. /Sec 30/ is fulfilled if mmis chosen so large that, with sufficient probability, the malicious participants never gain the upper hand in a majority decision.
Table 1: Probability that with 10 Score Managers, the malicious participants form a majority/tie.
Table 1 shows that under the assumption that only a small proportion of participants are malicious^(86){ }^{86}, 10 participants as Score Managers lead to reasonable results.
The initialization of the Score Managers is done as follows:
iisends their local trust vector vec(c)_(i)\vec{c}_{i}, p_(i)p_{i}and B_(i)B_{i}to all j inM_(i)j \in M_{i}.
All l inA_(i)l \in A_{i}report to all j inM_(i)j \in M_{i}. The jjthereby receive A_(i)A_{i}.
If jjknows B_(i)B_{i}, jjcan request the Score Managers M_(l)M_{l}for all l inB_(i)l \in B_{i}. After the exchange, the Score Managers j inM_(i)j \in M_{i}have the necessary knowledge to execute the distributed EigenTrust algorithm instead of ii.
Definition
Let kkbe the round index and i,ai, abe participant indices.
compute_round(k,i,a)=(1-a)(step(k,1,i)+step(k,2,i)+dots+step(k,n,i))+ap_(a)compute\_round(k, i, a) = (1-a) (step(k, 1, i) + step(k, 2, i) + \ldots + step(k, n, i)) + a p_{a}
The definition differs from the simple distributed algorithm only by the possibility of choosing an index for ppdifferent from ii.
Algorithm 3:
Simplification: m=1m=1 Each participant aareceives:
vec(c)_(i)\vec{c}_{i}, A_(i)A_{i}, B_(i)B_{i}, where iiis any element of the set of all participants.
1: k=0k = 0; 2: Ask all participants j inA_(i)j \in A_{i}for t_(j)^((0))=c_(ji)p_(j)t_{j}^{(0)} = c_{ji} p_{j}; 3: repeat 4: quadt_(i)^((k+1))=compute_round(k,i,a)\quad t_{i}^{(k+1)} = compute\_round(k, i, a); 5: quad\quadSend step(k+1,i,j)step(k+1, i, j)to the participants l inM_(j)l \in M_{j}AA j inB_(i)\forall j \in B_{i}; 6: quad\quadWait for the receipt of step(k+1,j,i)step(k+1, j, i)from l inM_(j)l \in M_{j}AA j inA_(i)\forall j \in A_{i}; 7: until distance() < epsilondistance() < \epsilon;
Discussion
The function compute_round()compute\_round()has been given another parameter that allows indexing ppwith a value other than ii. Indexing with aaensures that the pre-trusted participants remain anonymous even in the secure algorithm. Compared to the source [Kamvar Schlosser Garcia-Molina 2003], the core of the secure algorithm has been significantly modified. The Score Managers send their intermediate results to the Score Managers of the participants who rated their daughters and receive the intermediate results from the Score Managers of the participants who submitted ratings about the daughters. These senders and receivers are precisely the participants who need the values for further calculation. The number of messages exchanged is thus reduced because the detour via the daughters is eliminated during transmission. Furthermore, security is increased because the daughters no longer participate in the calculation and can therefore not manipulate it.^(87){ }^{87}
6.6.8 Use of Global Trust Values
The use of the global trust values for the scenario given in this thesis differs significantly from the way they are recommended in [Kamvar Schlosser Garcia-Molina 2003] for file-sharing networks. There, the trust value t_(i)t_{i}is interpreted as the probability with which a participant decides to download from participant ii. Arguments that with a simple tactic like "the best trust value wins", participants with high values would be overloaded, do not apply to online auctions. Rather, it is in the sellers' interest to get as many bidders as possible.
6.6.8.1 Selecting an Auction
First, a tactic for bidders to select potential auctions will be presented. Auctions inherit the trust value of their seller. When searching for suitable auctions, the trust value of the seller is taken into account when sorting auctions. Auctions with higher trust values are therefore ranked higher in the search results. From a business perspective, this has the interesting side effect that auctions with lower trust values will achieve lower prices. This means, conversely, that bidders with a higher risk tolerance (who choose auctions with lower trust values) achieve better prices. For the seller, in turn, there is a strong motivation to achieve a high trust value, as they can achieve higher prices this way.
6.6.8.2 Allowing Bidders
As a seller, there is a clear conflict of interest: The aim is to maximize the number of bidders in order to maximize the price, while at the same time only allowing trustworthy bidders to participate. EigenTrust ignores distrust through normalization. New participants are therefore indistinguishable from malicious ones. This circumstance is unfortunate but hardly avoidable, since any participant with negative global trust would immediately change their identity anyway. It seems a good compromise to give the seller the opportunity to specify what percentage of the total number of participants they want to exclude from the auction. This way, the risk in auctions of valuable goods can be minimized.
Influencing the price according to a formula such as (1-t_(i))**"Price"(1 - t_{i}) * \text{Price}, which establishes a relationship between price and trust, is not helpful, as this would still allow malicious participants to submit unrealistically high bids.
6.6.8.3 Incentive System
The use of global trust values, as described in the last two sections, creates an incentive system that positively influences the overall behavior in the network.
To successfully conduct auctions, a seller needs a high trust value, since according to /Ann 20/, they are in strong competition with other sellers. As a consumer, a participant also needs a high trust value to be able to participate in as many auctions as possible. The participants in the network therefore collectively strive for high trust values, which can only be achieved through positive behavior. Participants who have achieved a high trust value want to keep it and therefore avoid opportunistic actions that could endanger their reputation.^(88){ }^{88}
6.6.9 Attack Scenarios
[Kamvar Schlosser Garcia-Molina 2003] presents various attack scenarios on a P2P network using EigenTrust. However, the changed use of the global trust values within the scope of the adaptation invalidates the statistical evaluations. Carrying out adapted simulations is beyond the scope of this thesis but is recommended. It should be noted that a simulation within the framework of an online auction, due to the multitude of human decisions, has to consider far more economic and sociological aspects than in a file-sharing system with participants acting based on probabilities.
The fundamental risks are posed by individual malicious participants, malicious collectives, and the so-called Sybil attack, which is a variant of the first two.
6.6.9.1 Individual Malicious Participants
Individual malicious participants have no way of achieving high trust values in a network secured by EigenTrust without behaving benevolently for a long time. Since this can only be done by conducting auctions, achieving a high trust value for a single malicious participant can only be achieved through high monetary expenditure.
Due to the assumption (/Ann 60/) that the vast majority of users are benevolent, it is ensured that the majority decision used in the secure EigenTrust algorithm leads to a correct result with high probability.
6.6.9.2 Collectives of Malicious Participants
A collective of malicious participants attempts to circumvent the rating system in a coordinated manner by having the participants in the collective rate each other well, but give bad ratings to the outside. A naive strategy does not work, as EigenTrust is able to break up such collectives by considering the pre-trusted participants. A more successful strategy is one in which selected participants, the spies, behave benevolently outside the collective but also give good ratings to participants within the collective. In this way, a relatively good ratio (from the perspective of the malicious participants) between good and malicious behavior can be achieved. As a countermeasure, it would be conceivable that relationships between participants could be disclosed as soon as massive misconduct occurs, so that spies can be exposed.
6.6.9.3 Sybil Attack
The greatest danger for the EigenTrust algorithm comes from the so-called Sybil attack. This is characterized by a malicious participant automatically creating such a large number of other ghost participants that they achieve a dominant position in the network. For example, the Score Manager method can be circumvented by the ghost participants always having a majority. EigenTrust itself cannot ward off this form of attack. A possible countermeasure would be to associate the creation of identities with costs (time), which would, however, require the establishment of a central institution.
Since a very large number of artificially created participants is required to outsmart the secure EigenTrust algorithm (enough to obtain a majority in the majority decisions of the Score Managers), a very simple technical countermeasure is also conceivable. By linking an identifier to a specific IP address and port number, the effort required to operate many participants simultaneously would increase significantly.^(89){ }^{89}However, over 65,000 participants could still be operated per IP address. This number can be further reduced if the usable ports were limited to a few (10-100 different, identical ports for all participants).
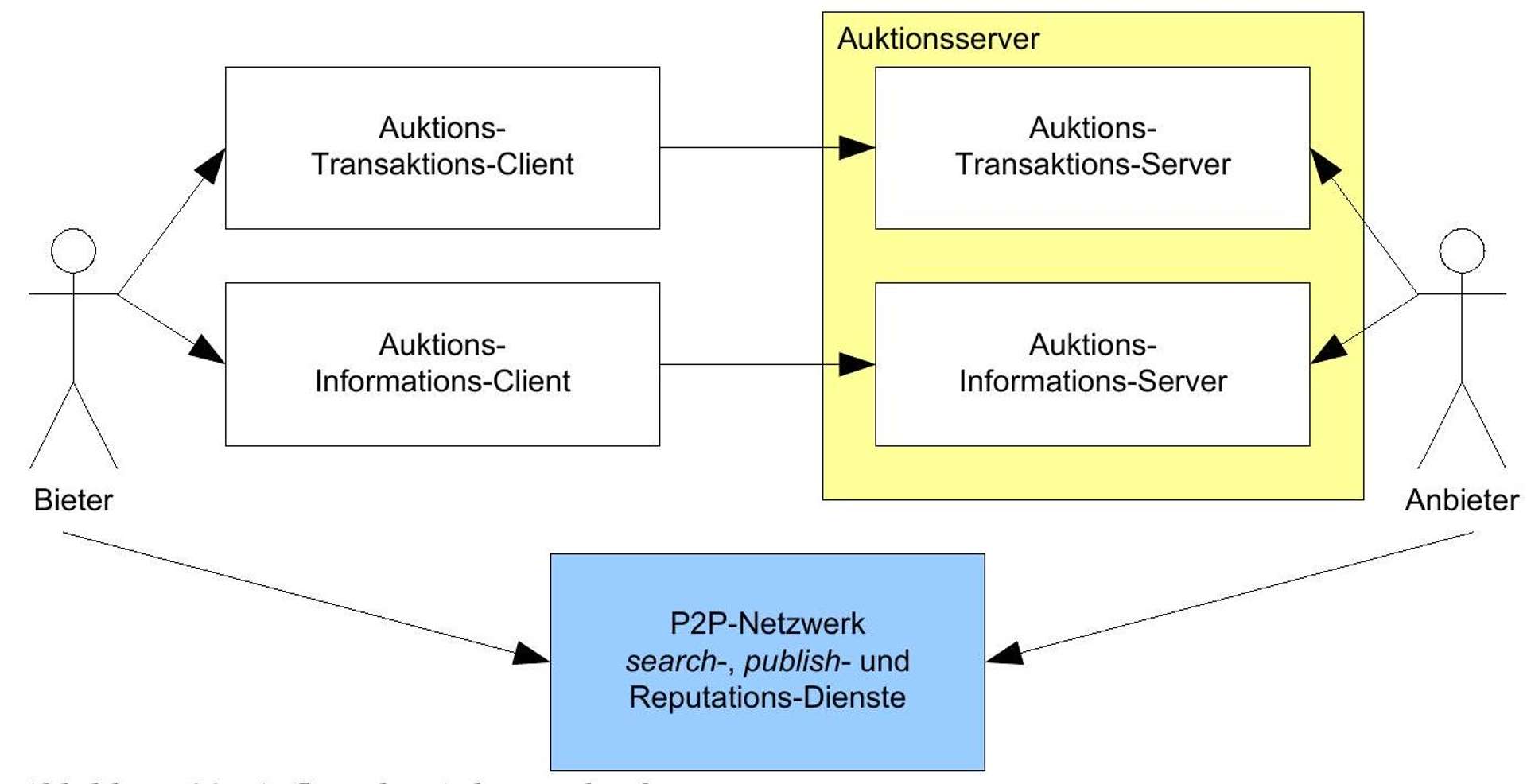
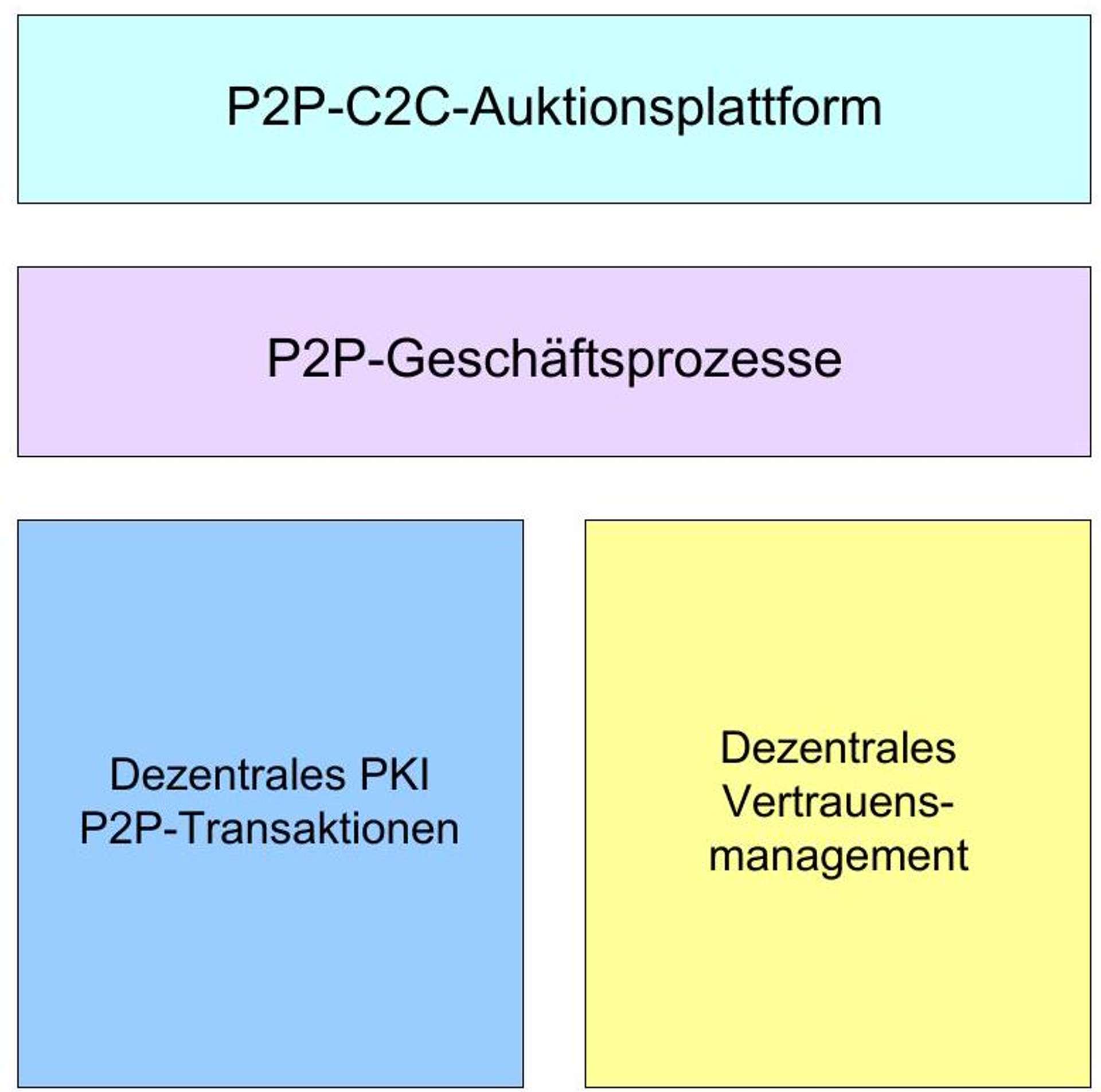
7 PKI for Online Auctions in P2P Networks
Traditionally, public key infrastructures have been developed for use within a company or in business-to-business communication. However, in such a context, decisions are made that make their use in a consumer-driven environment impractical. The other extreme, represented by PGP, are systems that do without complex bureaucracy but require a high level of technical understanding from users. Previous PKI developments have been characterized by a central assumption:
For the sender and recipient of a message or for the participants in a transaction, the natural identity^(90){ }^{90}of the other participant is relevant. This assumption is plausible for a large number of use cases. Especially when existing business processes are to be mapped to electronic media, there must be a possibility to find existing business contacts in the new system. Moreover, only a few business processes take place entirely within a PKI - personal contacts often remain indispensable. The user must therefore be given a way to establish a relationship between virtual and real contacts, which is usually implemented by using natural identities in the developed system.
The downside of natural identities is the difficulty of finding the appropriate public key for that identity - the public key problem.^(91){ }^{91}If this did not exist, the need for bureaucratically complex certification procedures or other trust models^(92){ }^{92}for key verification would be eliminated. When designing a PKI, it should therefore be examined whether the natural identity is relevant.
The C2C online auctions considered in the scenario of this thesis offer ideal conditions for price formation that is satisfactory for both sides of the transaction due to the large number of sellers and buyers. The large number of buyers only comes into play because the market is completely transparent and offers can be searched efficiently. The selection of offers is based on the following criteria:
Need fulfillment
Price
Trustworthiness/Reputation of the seller^(93){ }^{93}
However, the natural identity of the seller is not among the criteria. The publication of the natural identity to arbitrary participants is not common on the Internet anyway.^(94){ }^{94}In summary, it can therefore be said that a PKI for use in the scenario does not necessarily have to offer an unambiguous way of mapping between a natural identity and the associated public key. For reasons of protecting consumer privacy, it can even be stated that such a (public) mapping must not exist at all.
The irrelevance of natural identity is a first striking feature of the business processes that the PKI developed here is intended to support. The transactions underlying the business processes always take place between exactly two participants in the P2P network, whereby one participant temporarily assumes the role of the transaction server and the other participant assumes the role of the client. It follows from the characteristics of a P2P network that there are no intermediaries between the participants in a transaction. Nevertheless, even participants with minimal mutual trust should be able to carry out transactions with each other. To make this possible, the non-repudiation service of the PKI must ensure that after a successful transaction, both the client and the server can show that it has taken place in order to hold the other party accountable if necessary. By using these P2P transactions, a similarly lively trade in goods and services is to be enabled among the participants of a P2P network as music files are exchanged in these networks today, without, however, creating a similarly lawless space.^(95){ }^{95}
7.1 Identifiers
Users of web applications usually identify themselves in the system by a freely selectable, system-wide unique string - the identifier. This fulfills, in addition to its technical function in the system, a function as a communication and memory aid for the people who use the system. The identifier must therefore be selectable in such a way that it is memorable. In decentralized P2P networks, however, the assignment of such an identifier is technically difficult, and therefore a string is usually chosen as the identifier about which it can be said with sufficient probability that it is globally unique. These strings have the characteristic that due to their purely random composition, they are very difficult for people to remember, let alone pronounce. As an alternative, P2P systems are therefore implemented in such a way that the participants choose a pseudonym that does not have to be unique and is not used by the system itself. It is not possible to conclusively infer a specific participant from the pseudonym, so that all functions that require this must be performed by the system based on the identifier without user intervention.
7.2 Eliminating the Public Key Problem
Definitions
IIis the set of all identifiers. PPis the set of all public keys. Let L sub I xx PL \subset I \times Pbe a relation. If LLis known, the public key problem is solved.
Approach A way will now be proposed how the public key problem can be eliminated. Let LLin L sub I xx PL \subset I \times Pbe a mapping with Pub_(i)=L(Identifier_(i))Pub_{i} = L(Identifier_{i})and let Identifier_(i)=Pub_(i)Identifier_{i} = Pub_{i}so that I=PI=P.^(96){ }^{96}The assignment of the identifier to the public key is trivial because the identifier is the public key.
It remains to be examined whether public keys are globally unique. This is given, since otherwise it would be possible to find collisions, which would in turn mean that the public key method would also be unusable as an encryption method.^(97){ }^{97}To minimize the length of the identifier, a cryptographic hash value of the key can alternatively be used. IIis then given by I_(i)=hash(P_(i))I_{i} = hash(P_{i})AA i in P\forall i \in P. Whether a key ppbelongs to participant iican then be checked by: Identifier_(i)=hash(p)Identifier_{i} = hash(p).
7.3 PKI Design
Based on the technique described above for solving the public key problem, a PKI will now be presented using its components and services.
The complexity of the PKI is significantly reduced by the simple mapping between public key and identifier. In addition, the use of a time-stamping service is dispensed with, which has far-reaching implications. The primary goal of this PKI is to create the basis for performing P2P transactions. These are described in detail in Section 7.4.
7.3.1 PKI Components and Services
This chapter presents the components and services of the PKI. The structure from Chapter 5.2 is maintained for better comparability.
7.3.1.1 Certificate
Certificates are not necessary because identifiers and keys are directly linked to each other (in fact, one could consider using self-signed certificates to be able to use different keys for different purposes. However, it is questionable whether this provides any real benefit in view of the additional complexity and will therefore not be considered further here).
7.3.1.2 Certification Authority
Not applicable, as no certificates need to be issued.
7.3.1.3 Certificate Repository
Not applicable, as there are no certificates.
7.3.1.4 Certificate Revocation
Certificate revocation is not directly necessary in the context of this PKI. However, it must still be possible to exclude a key from further use should it be compromised. This is done by publishing a tuple with:
The revocation status of a key can be queried in the network by:
revoked(Identifier_{i}) = search(\text{Does a revocation exist for } Identifier_{i});
Before verifying a signature, it must be checked whether the public key is still valid. This is done by searching the network to see if a corresponding revocation statement exists.
If a private key is lost, revocation is no longer possible.
A major difference compared to a traditional PKI is that revocations are not timestamped. The resulting consequences are discussed below in section 7.3.1.9.
7.3.1.5 Key Backup and Recovery
Backing up the private key is of particular importance in this PKI, as losing it is equivalent to losing one's identity in the online system. One approach to key backup would be to use a secret-sharing mechanism^(98){ }^{98}. However, backup mechanisms will not be discussed in detail here.
7.3.1.6 Automatic Key Update
Not applicable, as keys have an unlimited lifespan.
7.3.1.7 Key History
Not applicable, as keys have an unlimited lifespan.
7.3.1.8 Cross-Certification
Not applicable, as there are no certificates.
7.3.1.9 Support for Non-Repudiation
Non-repudiation is achieved in a PKI by signing documents with the author's private key. To check whether a signature is valid, it must also be ensured that no revocation has been issued for the key. Since revocations are not timestamped, any author can subsequently deny their authorship by issuing a revocation. In applications that use the PKI, there must therefore be sufficient motivation not to issue revocations.
A special feature of this PKI with regard to non-repudiation is the P2P transactions. These are treated separately in Section 7.4.
7.3.1.10 Time Stamping
A time-stamping service is not used.
7.3.1.11 Client Software
The client software will not be discussed in detail for the time being.
7.3.2 Special Characteristics
7.3.2.1 Key Lifespan
PKIs that provide a loose link between identity and key can give keys a limited lifespan, after which a new key is associated with the same identity. This prevents an attacker from having unlimited time to find a key. The PKI discussed here does not offer this possibility - the level of security achieved is therefore lower than in PKIs with limited key lifespans. The client applications of the PKI must take this into account.
7.3.2.2 Loss of Identity
The loss of a private key means the loss of identity in the network. There is no way to unequivocally link data that is bound to a specific key by signature to a new key. If the private key is lost, a participant has no choice but to create a new identity and build a new reputation. After triggering a revocation, the described loss of identity occurs in any case. This can be seen as positive insofar as revocation can only be used as a withdrawal option for a transaction if the loss of identity is accepted.
The possibility of identity loss limits the set of applications that can use the PKI. If the loss of identity means too great a loss for the user, the PKI will not be used; if the loss is too small, the motivation to not use revocations would be too low.
In the C2C online auction scenario, the loss of the private key primarily means the loss of reputation. Since users generally strive for a high trust value, this is quite painful. However, there is always the possibility of building a new identity, so that the consequences for the user remain within reasonable limits.
7.3.2.3 Key Generation
Key (and thus identity) generation can be done decentrally by each participant. No central authority is needed to process registrations or the like.
7.4 P2P Transactions
As described in the introduction to this chapter, the PKI developed here is intended to support P2P transactions. P2P transactions are parts of business processes in which two participants agree on a further course of action. They are therefore comparable to the conclusion of a contract.
A P2P transaction has exactly two participants iiand jj, whereby, depending on the situation, one participant temporarily assumes the role of the transaction client and the other participant assumes the role of the transaction server.
Figure 18: Schematic representation of the scope of a P2P transaction.
P2P transactions do not have transactional properties^(99){ }^{99}in themselves. These must be implemented by the transaction system on the respective transaction server (see Figure 18). P2P transactions are a special interface for a transaction system and therefore only specify how a transaction is initiated and completed, but not what happens in the background on the server side. To understand why P2P systems require a special protocol for conducting transactions, the commit process of a database will be considered as a classic transaction system. After the client sends the 'commit' command, they do not yet know whether it will actually be successful. They will usually receive a corresponding response from the database. However, if this response does not arrive, the client does not know whether the transaction has actually taken place. If the response arrives, the server cannot be sure that the client has received it. This can, of course, be solved by a response from the client - and so on and so forth. However, no stable state can be established. If it has to be assumed that the underlying network is unstable or has low availability, an ordinary commit protocol will therefore not work sufficiently. P2P transactions use the inherent redundancy of the P2P system to ensure satisfactory execution of transactions despite the extremely volatile availability of individual participants. This means that a transaction can also be completed if the client is no longer reachable after sending the 'commit', and the client is able to learn the result of a transaction even if the server is no longer available after the transaction has ended. In the following, a protocol will be presented that supports the execution of such transactions.
7.4.1 P2P Transaction Protocol
A P2P transaction is a transaction that a participant iiperforms with another participant jj. The protocol ensures that after the transaction has run, both iiand jjagree on whether the run was successful or not. Note that if and only if iican provide proof, jjis also able to do so, and vice versa.
7.4.1.1 Definitions
A transaction is identified by a globally unique transaction identifier (TID).
The transaction type (TT) determines the type of transaction.
A transaction has m+1m+1steps. mmis a natural number greater than 6.
A transaction that is completed with 'success' is called a successful transaction.
A transaction that is completed with 'failure' is called a failed transaction.
7.4.1.2 P2P Transaction Flow
Figure 19: The phases of a P2P transaction.
A P2P transaction can be roughly divided into 3 phases^(100){ }^{100}. It begins with a handshake, after which the participants have agreed on a TID. In the transaction content, the transaction-specific communication is carried out. In the transaction completion, the transaction client confirms that they want to execute the transaction and receives notification of whether it was executed or not. A transaction between participant ii(client) and participant jj(server) is given by
The handshake phase serves to determine a transaction identifier. This must always be different for two different transactions to prevent replay attacks^(101){ }^{101}.
Messages 0 to 2 form a challenge-response procedure^(102){ }^{102}. Both participants answer a challenge so that neither of them can intentionally use a chosen number instead of a random number. Two pairwise different transactions can therefore also be distinguished with the same semantic content.
The TID is derived from the messages of the challenge-response procedure. This ensures that if iiand jjdo not cooperate (i.e., rand_(i)()rand_{i}()or rand_(j)()rand_{j}()was a true random number), the TID is unique and no replay of transaction content can be performed (if iiand jjcooperate, the purpose of a replay remains questionable, as they can only cheat themselves). The two identifiers are included in the TID so that it can always be checked via the signature whether a message actually belongs to the transaction.
Each message of the transaction (with the exception of the first) contains the hash value of the immediately preceding message. This puts the messages in a clearly traceable order, since a message can only be sent after the preceding message was known (and its hash value could be calculated). Furthermore, this can prevent another class of replay attacks, since the same hash value is only accepted exactly once by each participant.
A protocol for Content_(n)Content_{n}with 4 <= n < m-24 \leq n < m-2must be defined for each transaction type. In a simple transaction, there is exactly one such message. An example would be a message with the statement "Bid for auction XYZ, amount 15.00 Euro".
Cancellation Options
At any time before the transaction is completed, a participant can decide that they do not want to continue the transaction. The cancellation is done by sending a corresponding message. If this message is not sent, the cancellation is done by timeouts (the length depends on the respective transaction type).
Message Flow The messages of a transaction are sent alternately between two participants (cancellation messages are an exception). The time interval between two messages can be arbitrarily long for business reasons.
In message m-1m-1, jjsignals that a 'commit' could be successful^(103){ }^{103}. Message mmthen contains the 'commit' of the transaction client, and the following message confirms whether the 'commit' was successful or not. Furthermore, jjpublishes this last message.
After receiving message mm, jjcan prove that iiwants to execute the transaction. In message m+1m+1, jjconfirms that the transaction has been executed (or the opposite). In addition, jjpublishes message m+1m+1so that they can subsequently show that iicould know that the transaction has been executed.^(104){ }^{104}
Figure 20: The completion of a P2P transaction with simplified messages (content only) as a UML sequence diagram (form and notation loosely based on [Oestereich 2001]). The transaction server and client remain online during the entire process.
Figure 21: The completion of a P2P transaction. The transaction client goes offline before receiving the 'success' message. They find the message later via the search service of the P2P network.
7.4.1.3 Non-Repudiation
The fact that a transaction has taken place can be proven by iithrough: prove_(i)(TID)=message_(TID,m+1)prove_{i}(TID) = message_{TID, m+1}and by jjthrough: prove_(j)(TID)=message_(TID,m)^^search(publish(Identifier_(i),message_(TID,m+1),sig_(j)))prove_{j}(TID) = message_{TID, m} \wedge search(publish(Identifier_{i}, message_{TID, m+1}, sig_{j})). Note that message_(TID,m+1)message_{TID, m+1}must be searchable via search for jjto be able to provide their proof, which also means that iican provide their proof. After a P2P transaction, both iiand jjcan therefore always show that the transaction was carried out by mutual agreement. Note that it is a special characteristic of P2P networks that there is a massively redundant and practically arbitrarily scalable virtual data storage space that can be used via publish and search, which makes this mutual proof possible.
The proof of the existence of a transaction becomes invalid as soon as a participant publishes a revocation for their identifier, because revocations are not time-bound. Therefore, if a participant decides to publish a revocation after the completion of an electronic transaction (but before a possibly linked exchange of goods/money), the other participant can no longer prove that the transaction existed. Accordingly, it must be evaluated whether there is sufficient motivation in a specific application of the PKI not to issue a revocation.
7.4.2 Delay Tactic
A malicious participant could try to cheat the system by, in the role of transaction server, intentionally delaying the sending of the 'success' message in order to be able to show at any later time that a transaction has taken place.
If iinever receives a response after receiving the 'commit OK' message and sending their 'commit' message, they can publish messages m-1m-1and mm. They then serve as proof of the transaction until jjpublishes their message m+1m+1. This special case is shown in Figure 22.
Figure 22: The completion of a P2P transaction. The server no longer responds, although it has indicated that it would accept a 'commit'.
If jjemploys the delay tactic described in the last section, iican show specific proof of this:
That is, if iican show that they behaved correctly (they received 'commit OK' and sent 'commit'), but a 'success' or 'failure' message cannot be found, they have special proof that jjwants to delay the transaction. jjcan change this state at any time by publishing message m+1m+1. They will strive to do this as quickly as possible, as no one will enter into another transaction with jjif there is proof that they would delay a transaction.
7.4.3 Availability
A P2P transaction between iiand jjis completed if and only if the participant in the role of the transaction server, jj, has published the message m+1m+1belonging to the transaction via publish. The following applies: iidoes not have to be available to publish message m+1m+1. At the same time, jjdoes not have to be available for iito find out whether the transaction has been successfully completed.
7.4.4 Transactions and Reputation
After a P2P transaction has ended, the client and server can show third parties that the transaction has taken place. This allows a distributed reputation system to be built in which trust statements can be linked to a specific transaction. At the same time, trust statements can only be made if a transaction has actually taken place.
7.4.5 Implementation
P2P transactions could be implemented based on existing protocols for conducting transactions. It should be noted that the P2P transaction protocol is not in competition with existing transaction processing protocols. Rather, it is an extension to accommodate the special characteristics of P2P networks.
Possible implementation bases include the specifications Web Service Transaction^(110){ }^{110}(WS-Transaction) and Web Service Security^(111){ }^{111}(WS-Security) proposed by BEA^(105){ }^{105}, Microsoft^(106){ }^{106}and IBM^(107){ }^{107}, based on the Simple Object Access Protocol^(108){ }^{108}(SOAP) and the Web Services Description Language^(109){ }^{109}(WSDL). The P2P transaction protocol fits perfectly into this architecture. In fact, only the notifications would be partially implemented with the search and publish services of the P2P network.
The Secure Electronic Transaction^(112){ }^{112}(SET) protocol is not suitable, as it was specifically developed for payment processes with the participation of a financial service provider acting as an intermediary.
7.5 Conceptual Implementation of the Auction Platform
The public key infrastructure presented in the last section will now be applied to the example of the auction platform to demonstrate its practical applicability. For this purpose, selected use cases (see Chapter 3.1.6) are roughly implemented using the described functions.^(113){ }^{113}
Figure 23: Structure of the auction platform.
The implementation approach considers two components. The auction server (highlighted in yellow in Figure 23) provides the services for a specific auction, while the P2P network (highlighted in blue) as a whole serves as an abstract database in which information can be published and searched. The Auction Information Server serves as a source for current information (remaining time, current highest bid) regarding an auction, while bids are submitted on the Auction Transaction Server. For simplification, we assume that the servers run on the seller's computer. Such a strict relationship is not necessary, however, and could be resolved, for example, to increase availability.
Note that the introduction of an auction server does not in any way affect the P2P characteristics of the network as a whole, since every participant can provide one, and the role of the seller does not preclude the same participant from also acting as a bidder in other auctions.
7.5.1 Definitions
An auction aais identified by Identifier_(a)Identifier_{a}.
Auction Transaction^(114){ }^{114}is a transaction type (TT).
7.5.2 Functions
A value for the trustworthiness of a participant jjfrom the perspective of iican be determined by the function^(115){ }^{115}:
The data associated with an auction aa(see Figure 5) can be requested by the seller iithrough jj:
refreshAuction(Identifier_(i))=request_(i)(Identifier_(i),(^(')"Data for auction:"^('),Identifier_(a)))refreshAuction(Identifier_{i}) = request_{i}(Identifier_{i}, ('\text{Data for auction:}', Identifier_{a}))
7.5.3 Use Cases
7.5.3.1 /Af 10/ Evaluate Transaction
The use case "Evaluate Transaction" creates the database that serves as the basis for evaluating the trustworthiness of a person.
Regardless of the algorithm used to calculate the trustworthiness of a participant in a P2P network, a method will be proposed here that stores the reputation of a participant decentrally without the possibility of manipulation.
Abstractly, the use case is implemented as: publish("Trust statement with reference to transaction")publish(\text{Trust statement with reference to transaction})
The trust statements form the basis for a person's reputation. The following requirements apply to these statements:
They must be available to all participants in the network.
Statements may not be made on behalf of another participant.
Statements may only be created if a transaction has actually taken place.
Definition The transaction T_(t)T_{t}is the transaction with TID tt.
Procedure: iiand jjwant to make trust statements about T_(t)T_{t}. The fact that this transaction has taken place can be proven by both through prove_(i)(t)prove_{i}(t)and prove_(j)(t)prove_{j}(t), respectively. To meet the requirements described above, trust statements must therefore be supplemented with the TID and the respective proofs of execution. A trust statement is defined as:
Content contains the actual statement about trust.
A concrete implementation can limit ratings to successful transactions and transactions of a certain type (the type is contained in the TID). For the implementation of this use case, there is a restriction to successful transactions of the type Auction Transaction.
7.5.3.2 /Af 20/ Create Auction
As a result of the use case "Create Auction," the data of an auction is available in the P2P network. A seller iiputs an auction aaonline as follows: Identifier_(a)=(Identifier_(i),"Serial number")Identifier_{a} = (Identifier_{i}, \text{Serial number}); publish(Identifier_(a),"Description","Start time","End time","Starting price",sig_(i))publish(Identifier_{a}, \text{Description}, \text{Start time}, \text{End time}, \text{Starting price}, sig_{i});
An auction is identified in the network by the seller's identifier and a number assigned by the seller. The signature prevents a participant from placing an offer on behalf of another.
After an auction has been created, it can be retrieved using the search mechanism.
7.5.3.3 /Af 30/ Select Auction
The selection of an auction begins with a search for attributes of the description in auctions that are still active. In the result set, the current price, the number of seconds until the end of the auction, and the trustworthiness of the seller must be queried for each auction.
Algorithm: Participant iisearches for auctions: R=search("Auctions with properties and End time greater than Now")R = search(\text{Auctions with properties and End time greater than Now});
foreach (auction in R) {
refreshAuction(auction);
trust(Seller(auction));
}
The collected data is displayed to the participant, who can then make a decision based on the individual attributes of the auctions as to which auction they want to participate in. The incentive system^(116){ }^{116}created by the trust values is of particular importance for an auction process that is satisfactory for all participants.
7.5.3.4 /Af 40/ Submit Bid
The use case "Submit Bid" is the heart of the auction platform. It initiates the auction transaction. The bidders BBsubmit one or more bids to seller jj. The submission of the bid is the execution of a transaction with jj, initiated by i in Bi \in B. For each auction in which at least one bid has been submitted, there is exactly one auction transaction that is successfully completed. The submission of a bid by i in Bi \in Bto jjis done by: submit_bid(Identifier_(a),"Bid amount")=transaction_(ij)("'Auction Transaction'",(Identifier_(a),"Bid amount"))submit\_bid(Identifier_{a}, \text{Bid amount}) = transaction_{ij}(\text{'Auction Transaction'}, (Identifier_{a}, \text{Bid amount}))
Such a transaction can proceed in three different ways. The simplest case is when the execution of the transaction is immediately cancelled by the seller because the bid amount is not higher than the highest bid or the auction has already ended. Figure 24 shows the situation with a bid of insufficient amount. In addition to the objects for bidder and seller, the auction is shown. Its lifeline symbolizes the time until the end of the auction.
Figure 24: A bid is submitted but not accepted because the bid is not high enough.
If a bid is sufficiently high and the auction has not yet ended, the transaction initially continues until after the 'commit' has been transmitted by the bidder. As soon as another participant submits a higher bid, the seller sends a 'failure' message to the previous highest bidder to cancel the transaction.
Figure 25: A bid is submitted and accepted. Later, however, the bidder is outbid.
If no further bid is received, the last active bid wins the auction after the auction has ended. Accordingly, the seller transmits the 'success' message to the bidder.
Figure 26: A bid is submitted. Later, the bidder is notified that they have won the auction.
An auction consists of any number of transactions of the type Auction Transaction. However, a maximum of one transaction per auction is completed with 'success'. This transaction wins the auction. An auction in the sense of this system is thus a selection process between auction transactions based on the amount of the bid within a certain period of time. By sending or publishing the 'success' message, a purchase contract becomes effective between the bidder and the seller. Thus, the online auction modeled here corresponds exactly to the concept described in Section 3.1.1.
7.5.4 Conflict Scenarios
As complex as the business process of an online auction is, so too are the possibilities for conflicts between participants. Here, for selected cases, it will be shown how the system supports conflict resolution.
Conflict: Bidder iiclaims not to have submitted a bid for auction aato seller jj. Since submitting a bid is a transaction, jjcan prove that it took place. The link between the proof prove_(j)(TID)prove_{j}(TID)and a given auction is made by tracing the hash values that firmly link all messages of a transaction to it. This way, jjcan show that iisubmitted a bid for auction aawith a certain amount.
Special Case: A revocation has been sent for the bidder's key.
The proof described above is now invalid. ii's claim that they never submitted a bid cannot be refuted by means of the auction platform. The revocation has thus served its purpose. The misuse of revocation to withdraw from any transaction must be prevented. This is guaranteed because a revocation means that a participant loses their entire reputation. However, since participants strive for a high reputation^(117){ }^{117}, they will not use revocation lightly. An exception are those participants who were created solely for fraud. However, these should not have a high reputation and can be excluded from bidding on this basis.
Conflict: Seller claims not to have received a bid.
If the underlying transaction has been fully completed, the bidder can prove that they submitted a bid. It is generally assumed that a seller has no interest in not accepting a bid, since they strive for profit maximization.
Fraud: Seller bids on their own offer with their own second user.
It may be in the seller's interest to bid on an item themselves if the price achieved is not high enough. This cannot be prevented in the auction platform described.
7.5.5 Availability
A special feature of the P2P-based auction platform is that the seller must be online during the entire time. Here, it must be assumed that, even if the system as a whole always works, individual auctions cannot be completed or are interrupted quite often due to technical problems. However, various failover strategies are conceivable, as well as outsourcing the hosting of an auction to an external service provider. Such a service provider would play a similar role to eBay in conducting auctions. The difference, however, is that within the same platform, different service providers could compete, which would optimize the price of the service from the consumer's point of view.
7.6 Summary
The basic prerequisite for implementing a P2P C2C auction platform is the possibility of carrying out business processes within the P2P network. The P2P business processes are based on the primary components PKI and trust management, each of which is organized in a completely decentralized manner.
Figure 27: Primary components of the P2P C2C auction platform.
The PKI and, in particular, the P2P transactions enable the execution of complex business processes under the conditions of a P2P network without the existence of an intermediary who monitors the course of the transactions. Decentralized trust management, on the other hand, makes it possible to build a basis of trust between complete strangers and fulfills a probably even more important function by acting as a collective motivation to behave positively in the system.
In combination, the components create an environment that comprehensively supports business processes in P2P networks by creating the prerequisites for both technical functionality and human interaction.
7.7 Application Spectrum
In Chapter 5, public key infrastructures were referred to as application enablers. The PKI designed in this chapter is likewise by no means only suitable for use in online auctions but can help a wealth of applications to be implemented with P2P technology.
Whether an application can be implemented within the framework of the PKI in a P2P network primarily depends on whether an unambiguous mapping between public key and natural identity is required and whether the loss of identity due to the loss of a key is acceptable. While most B2B and B2C applications are excluded by these criteria, there are a large number of applications in the C2C area that can be supported by the PKI. In contrast to client-server applications, the operation of P2P applications in the C2C area is much more attractive because the operating costs are significantly lower. There is therefore great potential for new applications to be developed that were previously not feasible for cost reasons.
Established applications that could be implemented based on the PKI with P2P technology include rating websites such as Epinions.com^(118){ }^{118}and the Internet Movie Database^(119){ }^{119}, online marketplaces such as Mobile.de^(120){ }^{120}, online games such as Ultima Online^(121){ }^{121}or services for social networks such as Friendster^(122){ }^{122}and Orkut^(123){ }^{123}. However, use in the infrastructure area would also be conceivable, for example, as an extension of SMTP to prevent spam emails.
8 Summary and Outlook
8.1 Summary
This thesis developed an infrastructure that allows the execution of complex business processes in P2P networks. The discussion was based on a consistent scenario - a C2C online auction platform - which put the theoretical concept into a business perspective. As a basis for further presentation, an introduction to P2P networks, cryptography and public key infrastructures was given. In the further course, the influence of trust on the course of business processes was considered, and a metric for managing trust between the participants of a P2P network was presented in detail. Finally, using the technologies described, procedures were established that enable the goal of the thesis, the execution of business processes in P2P networks. Significant for supporting spontaneous behavior of the participants in the network despite relatively high security standards is, in particular, the elimination of the need to verify the validity of a public key. Furthermore, using the characteristics of the P2P network, a protocol was developed that enables the execution of transactions between network participants even in environments with volatile network connections. These P2P transactions, in conjunction with decentralized trust management, implement business processes in P2P networks. To demonstrate the practical applicability of these technologies, selected use cases of the scenario underlying this thesis, the C2C online auction platform, were then conceptually implemented.
8.2 Application in the Schaffhausen Communication Group
P2P technology offers interesting application possibilities for parts of the Schaffhausen Communication Group. These relate both to the technology itself and to user needs changed by P2P, for which special offers could be designed. The following ideas could be used as starting points for further consideration. The classic Internet user is characterized by primarily retrieving information. For this, they need a relatively low upload speed and a high download speed. Accordingly, most modern broadband Internet access is designed asymmetrically. The P2P user needs a different performance profile because they also offer services themselves. There is therefore potential for success by providing symmetrical broadband access that is specifically tailored to the needs of P2P users.
Classic billing systems, especially those based on billing individual transactions, are only partially suitable for use in P2P networks. Here, too, there is some potential to offer billing concepts that are directly tailored to the needs of P2P network providers. Since the costs for operating servers (hardware, administration, traffic, etc.) are eliminated in P2P networks, projects that are billed via kickbacks by telephone or SMS can also be operated profitably at lower costs for the customer. The use of P2P technology in MMS, GPRS, or UMTS networks could enable products that are significantly cheaper than the competition.
Know-how in the P2P area helps, not least, in the development of solutions for Voice over IP telephony, which is a classic P2P application.
The field of e-learning could also benefit greatly from P2P technology. Not only is the operation of a serverless e-learning platform attractive, but the more accurate mapping of human relationships in P2P networks could also be very attractive pedagogically.
The special core competence in the area of gambling could be used, possibly in cooperation with the lottery companies, to develop innovative online gambling concepts that fully exploit the characteristics of P2P networks. In particular, short-term bets and games of chance in which customers meet directly or compete against each other could be implemented in this way.
8.3 Outlook
The technology presented and developed in this thesis could gain importance in many areas in the future, as a large number of applications could benefit immensely from a port to P2P technology and the resulting cost-saving potentials. However, the switch to the P2P architecture also raises questions that are beyond the scope of this thesis but nevertheless deserve closer consideration. These include a detailed business analysis of the changes in costs and performance of P2P applications compared to traditional applications, as well as an analysis of the legal and social changes with regard to the roles of Internet customer and Internet service provider.
As stated in the introduction, the goal of this thesis was to assemble the building blocks for conducting complex business processes in P2P networks. We now face the exciting task of using these building blocks to build the applications that will bring us closer to the vision presented in the introduction of the emancipated Internet user who freely switches between the roles of customer and provider.
References
[Adams Lloyd 2002] Carlise Adams, Steve Loyd; Understanding PKI: concepts, standards, and deployment considerations; Boston, 2002 [BEA] BEA Systems; http://bea.com (Retrieved on 01.07.2004) [Beutelspacher 1998] Albrecht Beutelspacher; Moderne Verfahren der Kryptographie: von RSA zu Zero Knowledge; Braunschweig, Wiesbaden, 1998 [BitTorrent] The Official BitTorrent Home Page; http://bitconjurer.org/BitTorrent/ (Retrieved on 14.07.2004) [Brin Page 1998] Larry Page, Sergey Brin, R. Motwani, T. Winograd; The PageRank Citation Ranking: Bringing Order to the Web; Stanford University, 1998 [Brookshier Govoni Krishnan 2002] Daniel Brookshier, Darren Govoni, Navaneeth Krishnan; JXTA: Java P2P Programming; Indianapolis, 2002 [Buchmann 2004] Johannes Buchmann; Einführung in die Kryptographie; Berlin, Heidelberg, New York, 2004 [Buyya 2004] Rajkumar Buyya; Grid Computing Info Centre: FAQ; http://www.gridcomputing.com/gridfaq.html (Retrieved on 11.08.2004) [ClusterGridP2PComparisson] P2P Journal - Grid Computing; http://p2pjournal.com/main/grid.htm (Retrieved on 03.08.2004) [DNS 1987] RFC 1035 - Domain names - implementation and specification; http://www.faqs.org/rfcs/rfc (Retrieved on 16.07.2004) [Dustdar Gall Hauswirth 2003] Schahram Dustdar, Harald Gall, Manfred Hauswirth; Software-Architekturen für Verteilte Systeme; Heidelberg, Berlin, 2003 [eBay] Die eBay Website; http://www.ebay.de (Retrieved on 02.06.2004) [eBay AGB] AGB für die Nutzung der deutschsprachigen eBay-Websites; http://pages.ebay.de/help/policies/user-agreement.html (Retrieved on 06.07.2004) [Epinions] Epinions, Inc; http://www.epinions.com/ (Retrieved on 16.07.2004) [Feisthammel 2002] Patrick Feisthammel; Explanation of the web of trust of PGP; http://www.rubin.ch/pgp/weboftrust.en.html (Retrieved on 17.05.2004) [Friendster] Friendster, Inc.; http://www.friendster.com/ (Retrieved on 16.07.2004) [Google] The Google Website; http://www.google.com (Retrieved on 12.08.2004) [Haveliwala Kamvar 2003] Taher H. Haveliwala, Sepandar D. Kamvar; The Second Eigenvalue of the Google Matrix; Stanford University, 2003 [IBM] International Business Machines Corporation; http://www.ibm.com/us/ (Retrieved on 12.08.2004) [ICQ] ICQ Inc.; http://www.icq.com (Retrieved on 14.07.2004) [IMDB] The Internet Movie Database; http://www.imdb.com/ (Retrieved on 16.07.2004) [JXTA] JXTA - Java P2P Framework; http://www.jxta.org/ (Retrieved on 16.06.2004) [Kamvar Schlosser Garcia-Molina 2003] Sepandar D. Kamvar, Mario T. Schlosser, Hector Garcia-Molina; The EigenTrust Algorithm for Reputation Management in P2P Networks; published in Proceedings of the Twelfth International World Wide Web Conference, 2003. [Kazaa] Sharman Networks; http://www.kazaa.com/us/index.htm (Retrieved on 14.07.2004) [Ledlie Shneidman Seltzer Huth 2003] Jonathan Ledlie, Jeff Shneidman, Margo Seltzer, John Huth; Scooped, Again; published in 2nd International Workshop on Peer-to-Peer Systems (IPTPS '03) [Lucking-Reiley Bryan Prasad Reeves 2000] David Lucking-Reiley, Doug Bryan, Naghi Prasad, Daniel Reeves; Pennies from eBay: the Determinants of Price in Online Auctions; Vanderbilt University, University of Michigan, 2000 [mau 2003] pseudonymous, secure and decentralized messaging system; http://www.advogato.org/person/mau/diary.html?start=3 (Retrieved on 19.05.2003) [Maymounkov Mazieres 2002] Petar Maymounkov and David Mazieres; Kademlia: A Peer-to-peer Information System Based on the XOR Metric; NYU, 2002 [Microsoft] Microsoft Corporation, Inc; http://www.microsoft.com (Retrieved on 01.07.2004) [mobile.de] mobile.de; http://mobile.de/ (Retrieved on 16.07.2004) [Mui Mohtashemi Halberstadt 2002] Lik Mui, Mojdeh Mohtashemi, Ari Halberstadt; A Computational Model of Trust and Reputation; Massachusetts Institute of Technology, 2002 [Napster] Napster Inc.; http://web.archive.org/web/20001217233000/http://www.napster.com/ (Archive from 17.12.2000) [Oestereich 2001] Bernd Oestereich; Objekt-orientierte Softwareentwicklung; München, 2001 [Orkut] Orkut; http://orkut.com/ (Retrieved on 16.07.2004) [Patton Jøsang 2004] Mary Anne Patton, Audun Jøsang; Technologies for Trust in Electronic Commerce; Distributed Systems Technology Centre, 2004 [Pfister 1998] Gregory F. Pfister; In Search of Clusters; London, Sydney, Toronto, 1998 [Ratnasamy Francis 2001] Sylvia Ratnasamy, Paul Francis, Mark Handley, Richard Karp, Scott Shenker; A Scalable Content-Addressable Network; published in Proceedings of ACM SIGCOMM 2001 [Ripenau Foster 2002] Matei Ripeanu, Ian Foster; Macroscopic Properties of Large-Scale Peer-to-Peer Systems; University of Chicago, 2002 [Saroiu Gummadi Gribble 2002] Stefan Saroiu, P. Krishna Gummadi, Steven D. Gribble; A Measurement Study of Peer-to-Peer File Sharing Systems; Univ. of Washington, 2002 [Schröder 2004] Hinrich Schröder; Vorlesungsbegleitende Unterlagen zum Wahlpflichtfach Informationsmanagement; Nordakademie, 2004 [SET 2003] RFC 3538 - Secure Electronic Transaction (SET); http://www.faqs.org/rfcs/rfc3538.html (Retrieved on 30.06.2004) [SETI@home] SETI@home: Search for Extraterrestrial Intelligence at home; http://setiathome.ssl.berkeley.edu/ (Retrieved on 14.07.2004) [Sit 2002] Emil Sit; Detecting Malicious Nodes in Chord; MIT, 2002 [SMTP 1982] RFC 821 - Simple Mail Transfer Protocol; http://www.faqs.org/rfcs/rfc821.html (Retrieved on 16.07.2004) [SOAP 2003] SOAP Version 1.2 Part 1: Messaging Framework; http://www.w3.org/TR/soap12-part1/ (Retrieved on 01.07.2004) [Steinmetz Wehrle 2004] Ralf Steinmetz, Klaus Wehrle; Peer-to-Peer-Networking & -Computing; published in Informatik Spektrum 20 February 2004 [Stoica Morris 2001] Ion Stoica, Robert Morris, David Karger, M. Frans Kaashoek, H. Balakrishnan; Chord: A Scalable Peer-to-Peer Lookup Service for Internet Applications; MIT Laboratory for Computer Science, 2001 [UA] ORIGIN - Ultima Online; http://www.uo.com/ (Retrieved on 16.07.2004) [Watts 2003] Duncan J. Watts; six degrees: the science of a connected age; London, 2003 [Which SSL] Which SSL - SSL Certificate Guide; http://www.whichssl.com/ssl-certificate-comparison (Retrieved on 18.06.2004) [Wikipedia ACID] ACID; http://en.wikipedia.org/wiki/ACID (Retrieved on 12.08.2004) [Wikipedia Auction] Auction; http://en.wikipedia.org/wiki/Auction (Retrieved on 05.07.2004) [Wikipedia Client-server] Client-server; http://en.wikipedia.org/wiki/Client-server (Retrieved on 02.07.2004) [Wikipedia Entity-Relationship Model] Entity-Relationship Model; http://en.wikipedia.org/wiki/Entity-relationship_model (Retrieved on 22.07.2004) [Wikipedia Gnutella] Gnutella; http://en.wikipedia.org/wiki/Gnutella (Retrieved on 14.07.2004) [Wikipedia Kryptographie] Kryptographie; http://de.wikipedia.org/wiki/Kryptographie (Retrieved on 17.05.2004) [Wikipedia Online auction business model] Online auction business model; http://en.wikipedia.org/wiki/Online_auction_business_model (Retrieved on 05.07.2004) [Wikipedia Pretty Good Privacy] Pretty Good Privacy; http://en.wikipedia.org/wiki/PGP (Retrieved on 02.08.2004) [Wiley 2003] Brandon Wiley; Distributed Hash Tables, Part I, 2003 [WS-Security 2002] Specification: Web Services Security (WS-Security); http://www-106.ibm.com/developerworks/webservices/library/ws-secure/ (Retrieved on 01.07.2004) [WS-Transaction 2002] Specification: Web Services Transaction (WS-Transaction); http://www-106.ibm.com/developerworks/webservices/library/ws-transpec/ (Retrieved on 01.07.2004) [WSDL 2001] Web Services Description Language (WSDL) 1.1; http://www.w3.org/TR/wsdl (Retrieved on 01.07.2004) [Xu Yadav 2003] Bo Xu, Surya Yadav; Effects of Online Reputation Service in Electronic Markets; published in Proceedings of the Ninth Americas Conference on Information Systems (AMCIS), 2003 [Yang Garcia-Molina 2003] Beverly Yang, Hector Garcia-Molina; Designing a Super-Peer Network; published in Proc. 19th Int'l Conf. Data Engineering [Ziegler Lausen 2004] Cai-Nicolas Ziegler Georg Lausen; Spreading Activation Models for Trust Propagation; Institut für Informatik, Universität Freiburg, 2004
1 See [SMTP 1982]. 2 See [DNS 1987]. 3 Cf. [Brookshier Govoni Krishnan 2002], p. 1ff. Brookshier explicitly refers to JXTA. However, the statement can be generalized. 4 Cf. [Dustdar Gall Hauswirth 2003], p. 167. 5 Cf. [Wikipedia Client-server].
6 Cf. [Steinmetz Wehrle 2004], p. 52. 7 Cf. [Brookshier Govoni Krishnan 2002], p. 8ff. 8 Cf. [Dustdar Gall Hauswirth 2003], p. 162.
9 The use of the word "incentive system" is correlated with its meaning in human resource management. See [Thommen Achleitner 2001], p. 681ff. 10 Cf. [Steinmetz Wehrle 2004], p. 53. 11 Cf. [Steinmetz Wehrle 2004], p. 52ff. 12 Cf. [Dustdar Gall Hauswirth 2003], p. 170, 177 and [Yang Garcia-Molina 2003], p. 1 ff.
13 Cf. [Steinmetz Wehrle 2004], p. 52. 14 Cf. [Steinmetz Wehrle 2004], p. 53. 15 Cf. [Pfister 1998], p. 5. 16 Cf. [ClusterGridP2PComparisson]. 17 Cf. [Buyya 2004]. 18 Cf. [ClusterGridP2PComparisson]. 19 See [JXTA]. 20 Cf. [Brookshier Govoni Krishnan 2002], p.10. 21 See [Napster]. 22 See [Kazaa]. 23 See [Wikipedia Gnutella]. 24 See [BitTorrent]. 25 See [SETI@home]. 26 See [ICQ]. 27 It should be noted, however, that systems like JXTA [JXTA] support smooth communication even in realistic network topologies (see [Brookshier Govoni Krishnan 2002], p. 52 ff). 28 Cf. [Saroiu Gummadi Gribble 2002], p. 9. 29 Cf. [Wikipedia Online auction business model]. 30 Cf. [Wikipedia Auction] and [eBay AGB], §9. Bartering, the sale of services, minimum prices, and starting prices are ignored for simplification.
31 Notation and form loosely based on [Oestereich 2001].
32 See [eBay].
33 This thesis considers web applications as a special case of client-server applications in which the entire business logic is mapped on the server and communication usually only runs at the client's request. For the purposes of the argumentation, the distinction is not necessary. 34 Of course, clients are free to communicate with each other using independent protocols (e.g., email, telephone).
35 Cf. [Beutelspacher 1998], p. 1 ff. 36 Cf. [Adams Lloyd 2002], p. 7ff and [Wikipedia Kryptographie].
37 Cf. [Adams Lloyd 2002], p. 10. 38 In fact, Diffie and Hellman initially only developed a key exchange method that has a slightly different communication flow. The described flow resembles that of using the RSA method (see [Beutelspacher 1998], p. 18).
39 The RSA signature method is described. The ElGamal signature method allows verification of the signature without recovering the message (see [Beutelspacher 1998], p. 31). 40 Cf. [Beutelspacher 1998] p. 13. 41 The required amount of entropy depends on the situation and will therefore not be discussed in detail here. 42 "Pervasive security infrastructure" was chosen as the translation for "durchdringende Sicherheitsinfrastruktur." 43 For this section, cf. [Adams Lloyd 2002], p. 21ff. 44 Cf. [Adams Lloyd 2002], p. 22. 45 For this section, cf. [Adams Lloyd 2002], p. 28ff. 46 The structure of the repository is not specified. Data storage can therefore be centralized or decentralized. 47 The concept is comparable to metaclasses that inherit from themselves. 48 Cf. [Adams Lloyd 2002], p. 132ff. 49 See [Which SSL]. Certificates from the market leader Verisign are available from $349 per year. 50 Cf. [Adams Lloyd 2002], p. 135ff. 51 See [Wikipedia Pretty Good Privacy]. 52 These will be the contacts whose keys can be obtained through personal exchange. 53 The small-world property of the underlying network makes this very likely. However, this was only proven after the development of the Web of Trust (see section 6.2). 54 Cf. [Adams Lloyd 2002], p. 142 and [Feisthammel 2002].
55 "Encounters" should be interpreted here in a very broad sense. In particular, virtual encounters are included. 56 Cf. [Mui Mohtashemi Halberstadt 2002], p. 5. 57 Cf. [Patton Jøsang 2004], p. 1. 58 See /Ann 50/. 59 Cf. [Ziegler Lausen 2004]. 60 See Chapter 5.3.2.
61 Also known as "six degrees of separation". 62 Highly simplified representation. Cf. [Watts 2003], p. 37ff and p. 132ff.
63 Cf. [Watts 2003], p. 44. 64 Cf. [Watts 2003], p. 88ff. 65 It is assumed here that the trust network underlying the P2P network is small. However, this cannot be proven without the network existing. The assumption is plausible, however, as this property has been shown for similar networks (see [Ripenau Foster 2002]) and small-world networks are common (only networks with very extreme properties are not small (see [Watts 2003], p. 90, Fig. 3.7)). 66 Cf. [Ziegler Lausen 2004], p. 1. 67 For /Ver 10/ to /Ver 50/ cf. [Kamvar Schlosser Garcia-Molina 2003], p. 1. 68 This requirement is important because in the course of aggregating a trust metric, knowledge about participants who are indirectly not connected with the current transaction is generated. 69 See [Google]. 70 See [Brin Page 1998].
71 The descriptions in this section are adapted from [Kamvar Schlosser Garcia-Molina 2003], pp. 2-4. 72 This method was chosen to keep the computational complexity of the algorithm low for distributed computation. The algorithm still achieves good results. 73 This is the left eigenvector of CC. 74 See [Brin Page 1998].
75 In English, they are called pre-trusted actors. This is therefore a special set of participants whose trust is treated differently than that of ordinary participants. 76 This also has the advantage that c_(ij)c_{ij}is always defined, since the possible division by 0 is eliminated. 77 Note that the formula deviates from the source after consultation with the authors. There it incorrectly states sum_(j)max(s_(ij))\sum_{j} \max(s_{ij}). 78 The definitions have been generalized compared to [Kamvar Schlosser Garcia-Molina 2003], Algorithm 3, to be applicable outside of a file-sharing service. 79 Note that iiknows this set. In an implementation, the set would have to be searchable, for example. 80 Cf. [Wiley 2003]. 81 See [Ratnasamy Francis 2001]. 82 See [Stoica Morris 2001]. 83 See [Maymounkov Mazieres 2002].
84 Cf. [Ratnasamy Francis 2001], p. 4. 85 The requirement for anonymity has been waived compared to the source [Kamvar Schlosser Garcia-Molina 2003], p. 5, since it is not problematic whether the Score Manager knows the identity of the participant whose trust value they are calculating. Due to /Sec 30/, the participant would only represent a minority anyway. 86 See /Ann 60/. 87 This change was made possible because the anonymity requirement for the algorithm was removed compared to the source. Algorithm 4 in [Kamvar Schlosser Garcia-Molina 2003] apparently violates this requirement itself in lines 6/7. 88 Cf. [Xu Yadav 2003], p. 406. 89 Cf. [Sit 2002], p. 1. 90 The natural identity here is, for example, the name of a company or person, as well as other attributes of these entities that identify them (see, for example, distinguished name [Adams Lloyd 2002], p. 73, footnote 1). 91 See Chapter 4.2.1. 92 See Chapter 5.3. 93 Cf. [Lucking-Reiley Bryan Prasad Reeves 2000], p. 1. 94 This is shown by the example of [eBay], which (in the C2C area) only displays a freely selectable identifier as user information. 95 In fact, the approach of conducting traceable business processes runs counter to most developments in the P2P area, which try to conceal the identity and actions of users through obfuscation tactics. 96 This approach is presented in part in [Sit 2002], [mau 2003] and [Ziegler Lausen 2004]. However, these sources do not examine the matter comprehensively. The general scope of the approach, its disadvantages, and limitations regarding applicability are not examined. 97 Proof approach: The number of prime numbers that can be found that are smaller than the key length has sufficient entropy. 98 See [Buchmann 2004], p. 235. 99 See [Wikipedia ACID]. 100 These are not to be confused with the concept of 2-phase commit in distributed transactions. 101 See [Beutelspacher 1998], p. 99. 102 See [Beutelspacher 1998], p. 98. 103 This is only a non-binding message and is therefore not to be confused with the first stage of a 2-phase commit. 104 Publishing the message m+1m+1can be interpreted as sending the message to all participants in the P2P network. Cf. /P2P 20/ and /P2P 30/. 105 See [BEA]. 106 See [Microsoft]. 107 See [IBM]. 108 See [SOAP 2003]. 109 See [WSDL 2001]. 110 See [WS-Transaction 2002]. Both Atomic Transactions and Business Activities could be used to implement P2P transactions. 111 See [WS-Security 2002]. 112 See [SET 2003]. 113 For simplification, the implementation only considers network-specific functionalities.